Great explanations @azouz110 and @Jrinne
I have the same understanding of $$ML1 as a standalone factor to be combined with other factors in a ranking system.
The use of either expanding window or sliding window should be dictated by your belief in the dynamics of financial markets.
a) If you use sliding window (short training period), you believe that the factors/rules that worked well in the previous training period (5-10 years) will work well in the future period too.
b) If you use expanding window (longer training period), you want to train the model using all available data and you believe that the performance of factors/rules is not time varying or you do not believe in the scenario from point a)
Of course both methods can be back tested and the results can dictated which method is better but bear in mind that overfitting testing set is not difficult.
Thank you Jim. My point here is that the testing predictions from the different models (generated by the walk-forward validation) are combined and then saved under a factor such as $ML1.
After that, you can do whatever you want with that factor.
Add it to a ranking system, combine it with other Machine learning predictions, with other regular factors...
I love the idea. I think Pitmaster has considered something similar to exponential weighting (not sure it is that exactly or that he would call it that). But whatever method one considers the final method could be determined by cross-validation.
Also could be done as model-averaging or even stacking or both used in a P123 node.
Ideally, using a sliding window or expanding window would be a member option to be cross-validated with his or her feature set.
BTW, the computational expense for a linear regression model would almost certainly be acceptable as regression models are super-fast
That should no longer be their main purpose. They should be used for getting a feel of other statistics, or for position management refinements. Here's why:
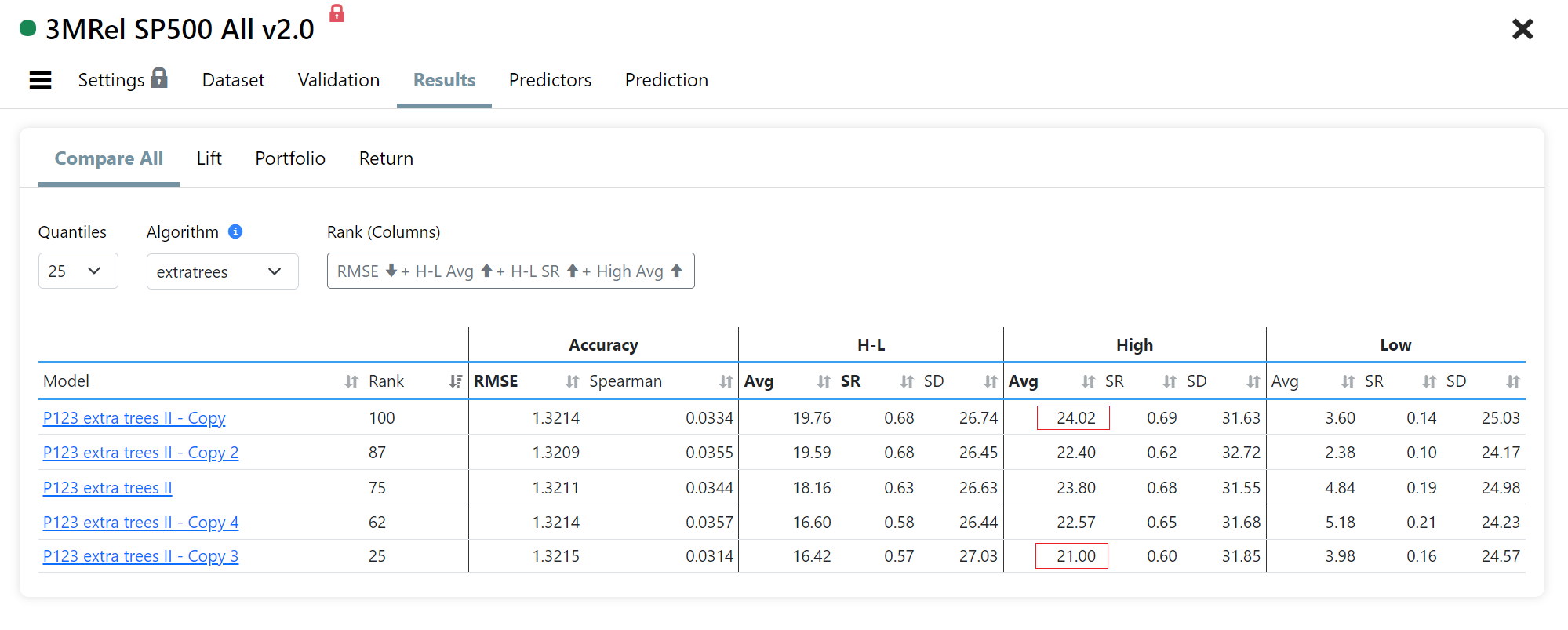
Below is my S&P500 AI factor validation results for the same exact model "P123 extra trees II" (a model is just an ML algorithm + settings). I made 4 clones and ran the validations over 20 years using "Blocked K-fold" w 4 splits. The H represents a portfolio of 20 stocks with the highest future 3Mo prediction, and L the 20 lowest predictions.
Check out the High Avg column. The annual returns range from 21% to 24%. A 3% annual difference is huge. With 10 stocks the range is 5%.
The reason is that the ExtraTrees has a certain level of randomness during the training. Running a simulation using one version of this model will give you one of an infinite set of possible outcomes. Could be a high one, or a low one. Most users now keep running simulations to get higher and higher performances. But the "real" performance is probably the lowest observed minus 2-3% more.
One of the goals of P123 AI Factors is to make this clear, and manage expectations
This randomness can be removed and is not necessarily a feature if n_estimators is small. From sklearn.ensemble.ExtraTreesRegressor: n_estimators* int, default=100*
A person wants to set this as high as possible and still get a good run-time. On a MacBook you can by with increasing it to 5,000 and still get a reasonable run-time. Well, that is if you use "sqrt" for max_features. This is equivalent to averaging the results of 500 runs using the default and the randomness will go away.
@marco if you have not done it already, you might look at setting max_features to "sqrt." It will run much faster and in theory could give better results.
The default is None. None literally increased the run-time exponentially and may degrade the results.
Using an AI factor in a simulation doesn't make a lot of sense to me. An AI factor is developed and trained using the same data that is used in the simulation. Perhaps I'm wrong, but using a simulation with an AI factor would therefore result in some lookahead bias. The only way to use a simulation with an AI factor without any lookahead bias would be to train the AI factor only on data that precedes the first date included in the simulation.
I may be completely wrong about this, though. If so, I'd be glad to be corrected.
Very true of many P123 backtests, to be sure. Something Marco, Azouz, Bob, Pitmaster and others would like to improve upon with different cross-validation techniques. Many in common use.
I think Azouz has something that does not do this and uses out-of-sample data in the sim. I understand that is the perception at P123 is different.
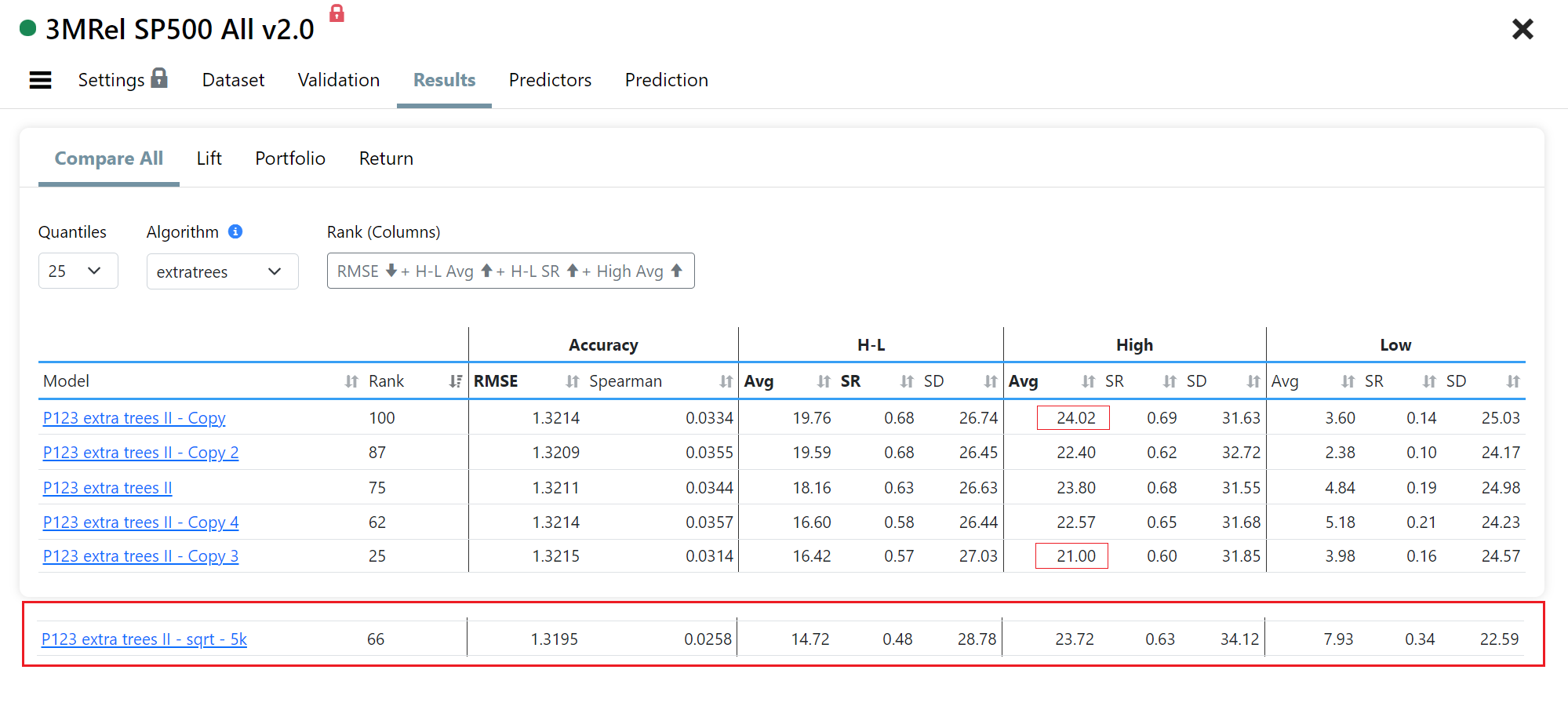
OK. Below is a comparison with our default ExtraTrees II. All parameters not present are default. Ran about twice as slow (2.5 minutes) and worst performance: higher SD in the H bucket and L bucket much worse. A 2nd version did slightly better, but not much.
We'll have a lot of fun with this...
P123 Extra Trees II: {"n_estimators": 200, "criterion": "squared_error", "max_depth": 8, "min_samples_split": 2}
P123 extra trees II - sqrt - 5k: {"n_estimators": 5000, "criterion": "squared_error", "max_depth": 8, "min_samples_split": 2, "max_features":"sqrt"}
This is actually a great result!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Decrease n_extimators to 500 and keep "sqrt" Should run 4 times faster no?. I get that I am the only one using my make and can let it run a while but a larger n_estimators is ALWAYS better.
Or if you keep it at 100 n_stimators: 2.5/500 the runtime!!!!!!!
0.005 times your present run-time if I did the math right!!!! Send some of your hardware back (decreasing your fixed cost and overhead including power usage) or use it for something else.
Yeah, 20 seconds with 500 estimators. Performance about the same, not great. So max_features = 1.0 seems like a winner.
We will make money by renting our machines, so if it takes longer, and results are better, everyone wins.
We ordered a LOT more machines. Buildouts start next week. We could have used a cloud but that just increases the cost for everyone. High performance machines on the cloud are very expensive.
I think it's the CPU architecture. We're getting much faster execution with older dual Intel vs. newer single chip AMD that on paper should outperform, by a lot.
In any event this is an SP500 model. Maybe for 1000+ stocks the executions time will be 4x. But if you are managing millions, what's literally a few bucks more for research? Our fastest ML server will be like $1.5/h
So if you look at what is being done internally with each split the program looks at all 300+ features when you use max_features = 1.0 vs sqrt(300+) or about 17 randomly selected features when using 'sqrt'.
It is just fewer calculations no matter how you look at it. So I would have to investigate further why my Mac started doing that--hoping to get some advantage from a significantly lower number of calculations needing to be done. I would try to update the program or something. For now my Mac gives me what I would hope for.
Maybe you can recruit a large number of parallel processors with your present workload. Probably something else. Guess it doesn't matter which I did not know.
I am not sure what this has to do with the simulations. I never used extra trees but in Lightgbm and xgboost, there is a random seed parameter that you can set to have all the clones always return the same result. Anyway, the possible outcomes you are referring to should not vary a lot and in the final, you would need to pick one version to generate the predictions.
If you are planning to buy let us say the top 10 predictions each rebalance period, you will have a very high turnover. By using for example a simulation, you can control the sell rule and sell only if the prediction falls below a specific threshold (ex: rankpos < 100), thus making the turnover lower. This is just one simple example.
Not at all. The prediction for a particular period are based on a model trained using an older period and thus there is no lookahead bias.
In fact, cross-validation using a time-series split is preferred over k-fold validation by many over at Sklearn for this very reason (also in the documentation(s) but Azouz is more clear and concise).
I might be wrong but I think Sim have been a big draw for P123.. I don't see how P123 could want to give Sims up if it was not absolutely necessary.
So maybe de Prado is right and P123 can keep sims if P123 would prefer to keep them? Some present members wish it were so, I think. Maybe some new members would like sims.
Personally, I need Sims in P123 classic to continue to do what Ii do now. I am pretty sure I will not stop using my present models. I am not sure that I will end up funding an AI/ML model (probably not actually). So I do request that any present use of sims with P123 classic not be restricted.
I am good with whatever P123 decides to do regarding Sims with the new AI/ML I do not really care. But I DO NOT think P123 is obligated to get rid of Sims with machine learning unless they just want to.
I get the impression that it may not be a computer-resource-management issue from this thread.
Not at all. Classic P123 will remain and continue to be developed. I just don't think they are critical to design AI strategies. The many new reports generated during model validation & testing are the main research tools.
Right now using AI factors in sims works, but it's slow. A sim that uses AI factors will take perhaps 10x longer to complete. That's because classic P123 and AI are two completely separate systems, one in C++ the other in Python.
Our focus is to first launch AI, then add more features to the AI workflow. Making sims that use AI factors faster will be something for later.
I don't understand why it would take longer. Once a model is selected, it is run once to generate predictions and those predictions are stored in a custom factor. Then all the sim has to do is to use that custom factor like we are now using custom factors with imported data.
We're not using custom factors to store the predictions. At the moment we're doing it on the fly. If you only use the AI factor inside a ranking system then it will be cached by the existing rank cache. So the second time you run a sim it will be super fast.