I don't know why you are doing the training on fly but you certainly have your reasons.
The thing that I don't understand is by doing that you are training the model over and over again using the same data to finally get the same prediction results.
What about rebalancing? Does this also train the AI model again?
I have an idea how to save $$$ for p123
Please consider allowing us to load pickle file with our own model and use the AI factor inside a ranking system/screener.
I think Pitmaster may be seeking greater control of the hyperparametrs used in his models by pickling and uploading them. Greater control of the hyperparameters would be good (if possible). I had thought restriction of access to the hyper parameters was a resource issue. For this reason, I had not suggested the idea. But resources do not seem to be as costly as I had once thought.
Also some changes in the hyper parameters would reduce the use of computer resources (e,g,, subsampling in XGBoost or dropout for neural-nets) and hyperparameters that lead to excessive run-times could be restricted. So that would not have to be an issue at all.
I believe there are probably good reasons to limit access to the hyper parameters that I am not aware of. So, just if it is possible, it would be nice to have greater access to the hyperparameters. And perhaps other members would like to have greater control also. Again, only if possible and/or any concerns could be addressed..
Previous examples in the forum: n_estimators (me above), monotonic_constraints (Pitmaster in another thread), random_seed (Azouz above). Also I suspect neural-nets will not work without some greater control of the hype parameters such as the use of dropout. Something that many people may come to notice, I believe.
Support vector machines (SVM) have some important hyperparameters including some that control whether it is linear model or not. To the point that one SVM with one hyper parameter has little resemblance on another SVM with different hyper parameters.
We're doing predictions, not training, on the fly using a stored "predictor". A Prediction is the output of the training stored in a pickle file. Think of it as a ranking system with weights fixed by the training.
Very error prone. Everything must match: features, order of features, preprocessor settings, distributions statistics when using z-score, etc. Also maybe some security concerns.
In any event we will let users supply their own hyper parameters. Naturally if you make a mistake, and your training runs for days, you are on the hook for it ($). But we need to make sure there are no security concerns here as well, like injecting malware via malicious hyperparam json.
Oh I see. I thought it was training because you said it takes lot of time. But model prediction should be very fast. However, I understand that part of the prediction is loading the factors and calculating the formula which should slow things down.
Hope caching prediction in a custom factor or somewhere else can be implemented soon.
Im trying to understand more of the price of using the ML models on the p123 platform. In the SPY 500 test that you describe above, how much will it cost to run such a test, and what will be the costliest part of running ML on P123? Is it the number of features, the length of the testing period (10 year vs 20 year) the complexity of each feature, or ?
The plan is to have three AI related revenue streams:
Validation / Training
This will be based on how much server power you use in $/hour. It will be priced similarly to what google charges for a compute instance in their cloud, and depends on how many CPUs you want and how much RAM you need. Additional CPUs benefit models that can run computations in parallel. For RAM it strictly depends on your dataset and hyperparams. There are 0 advantages to paying for RAM you don't need.
For reference my entire weekend long research would have been maybe $150 (100 hours of training) choosing the fastest servers.
Prediction (inference)
This will be a fixed monthly add-on cost to access the prediction engine which uses a trained model from your validation research. We're thinking $100-$150/mo for retail.
Storage
Dataset are preprocessed and stored in the AI backend, and take up a lot of space. The cost is based in Resource Units (25Mb = 1 RU). This is typically not an issue unless you never delete stuff. I have a ton of old garbage and I'm using around 50% of my RUs allocation of 10K. You can delete datasets to free up RUs.
So I got the impression this would be on top of an ultimate memberhship?
I think you just priced me out and I am a believer in what you are doing. But also I am someone who had a long time to work around some of the previous P123 limitations.
$100 monthly (additional) just to rebalance my ports being the largest expense, I believe.
FWIW for your marketing (pricing) information.
And @Marco, just a question. If the predictions can be done for $150 dollars for 100 hours ($1.5 dollars for a full hour!!!!!!), I might be good with you re-running the training and predictions each week on the less expensive server and adding the additional computing time of sorting the predictions with the output being the sorted predictions for say 25 of the highest ranked stocks (for a sell order RankPos <=25). I can figure out which of the stocks I hold are no longer on the list (and sell them) and then figure which of the 25 stocks that I do not hold to buy (starting with the highest ranked one). Why would that not be a savings for both of us?
AND TRUE ONLINE LEARNING (I.e, the model is RE- TRAINED EACH WEEK ON THE MOST RECENT DATA AVAILABLE)!!!
BTW, this could also be done with the downloads if daily downloads were available. For now, people who are good coders could save a lot of money (roughly $1,200 per year) downloading and using the API with machine learning models they have trained at home. I would consider that route if I ended up liking an XGBoost model or Extra Trees Regression (which I may end up liking at some point). Nice to have different options and just an observation.
So my point is someone who is really advanced will not be paying for that, probably, unless she is already rich from her investing and does not care about $1,200 per year. She will be using the API instead.
@Marco, those not signing up for machine learning are burning a lot or resources on the more expensive machine with optimization and sims? Not necessarily paying for all of it?. Like here: Machine learning vs. robust backtesting strategies. I am sure there math works from your point of view and I am missing something. But my spreadsheet, given my present models and my understanding of the AI/ML pricing from above, says I am priced out for now.
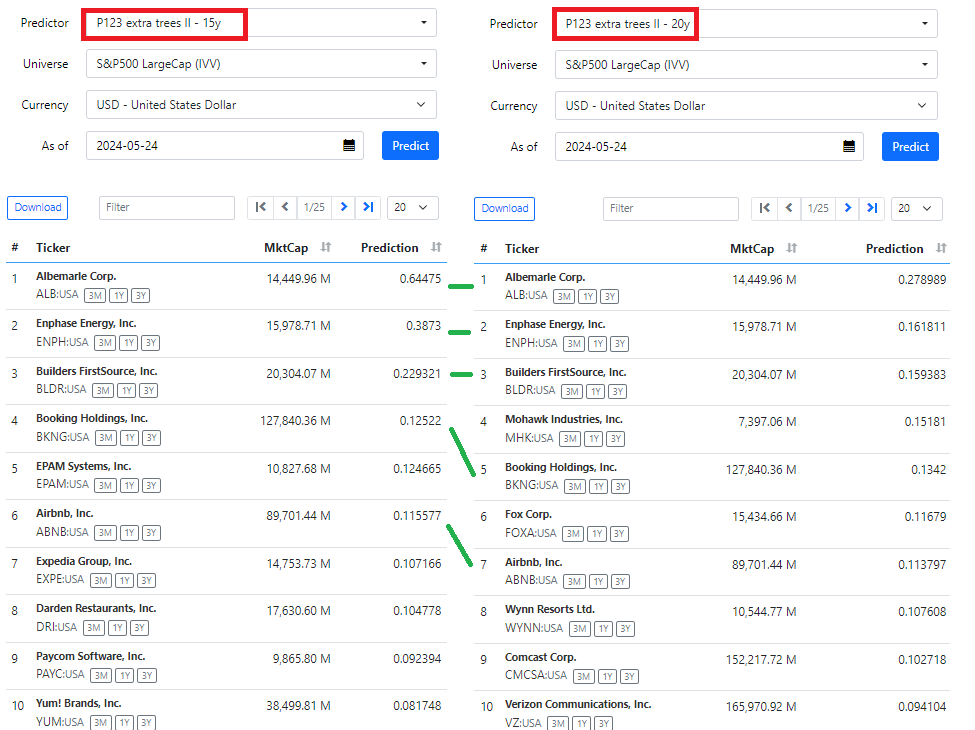
FYI, previously I stated that no top 10 stocks matched between two predictors trained with the same model but different dataset lengths (15y and 20y). Turns out we had a bug in the predictions. Turns out we were jumbling up the features. Below is the corrected top 10 predictions where 5 of 10 match. Something similar also happens with identical extra trees models trained with same dataset due to the randomness inherent in the algorithm.
Now the predictions looks better.
Previously the first model selected 4 commercial banks.
The screen with top 5 stocks from both previous models is below:
The top stock: ALB is interesting: core combination rank=10, slowing sales...negative q eps, mixed quality, high value, negative momentum (but improving) ... maybe Mr. random forest knows something special
How often would you need to access the prediction engine, will it almost work the same way as the screener works today? So to find your stock pick (or sell) of the week, you use this access.
How often will a model like this have to be re-trained?
It seems like the validation works much as the simulation, and the access as the screener?
So, I am still wrapping my head around this. That is $252 for a week (168 hours in a week). Or $13,146 dollars for a regular year or $13,176 for a lear year if that cost can be maintiaind with higher volumes. Economies of scale would be a beautiful thing..
Seriously, even with a reasonable mark-up could I reserve a year please?
So i get that is just the cost if I want P123 to develop and train a system, There is additional costs for rebalancing that system, running it as a Sim etc.
But a lot could be accomplished in just a week. If, for example, I already had a fixed set of factors (or features) already selected, I could run EVERY MODEL P123 will offer WITH EVERY REASONABLE HYPERPARAMETER PERMUTATION FOR EACH MODEL.
With less than 300 feature to start with you could, for sure, run every single model with every reasonable hyperparameter with recursive feature elimination (RFE). Sklearn RFE
And if you left a minute of time at the end of that week, run a holdout test set at the end. Or do nested cross-validation
If you are actually using Python for all of your coding, the code for nested cross-validation is included as an addendum below. Bottom line: less overfitting and a better idea of what real out-of-sample returns will be.
I guess I am going to suggest the option of a grid-search capability to start with this server cost in mind if P123 can handle the volume. Seems like a pretty obvious consideration at that price.
Or one could us a more efficient Bayesian Optimizer and reduce the overall cost of this (if you need to get it below or keep it at $1.50 per hour because of increasing demand). Examples:
Just if the capacity for the new members that would attract is there.
@marco, right now what you are offering can be done by advanced users at home (with a MacBook) for most AI/ML models (not support vector machines for example). Don't get me wrong, that is pretty cool. But you could step up your offering to a new level. To something that would be impossible to duplicate at home except for the most advanced user buying time with AWS or something similar to AWS. At $1.5 per hour you could provide near-professional capabilities to P123 members.
Seriously, if you have the option of expanding your servers (and keeping the same cost), you might talk to someone about this idea. Also, if your cost per user hour does not increase much, you might focus on increasing demand with new members and keeping the price low.
There will be demand for this. You won't have to convince the present forum to use this. The machine learning community (eg; at Kaggle), are already convinced. This is what they do, and know about, already.
Addendum (code for nested Cross-validation). Mostly for members using the API for now:
from sklearn.model_selection import GridSearchCV, cross_val_score, KFold
from sklearn.ensemble import RandomForestRegressor
import numpy as np
import pandas as pd
# Load your dataset
# df = pd.read_csv('your_dataset.csv')
# X = df.drop('target', axis=1)
# y = df['target']
# Define the model
model = RandomForestRegressor()
# Define the hyperparameters to tune
param_grid = {
'n_estimators': [100, 200],
'max_depth': [10, 20],
'min_samples_split': [2, 5]
}
# Set up the inner cross-validation for hyperparameter tuning
inner_cv = KFold(n_splits=5, shuffle=True, random_state=1)
outer_cv = KFold(n_splits=5, shuffle=True, random_state=1)
# Perform GridSearchCV within the inner cross-validation loop
clf = GridSearchCV(estimator=model, param_grid=param_grid, cv=inner_cv, scoring='neg_mean_squared_error')
# Perform nested cross-validation
nested_scores = cross_val_score(clf, X, y, cv=outer_cv, scoring='neg_mean_squared_error')
print(f"Nested CV Mean Score: {np.mean(nested_scores)}")
This is a question that more than just Marco can answer, but how do you move on from the trained model and the recommended stocks picked out based on the trained model:
How do you choose the weight in each stock
How many stocks do you choose to have in your live portfolio
TL;DR: With the API you will be able to sort predictions to create ranks and also be able to output (e.g., print) the predicted returns for dynamic weighting. In addition, you can use this any discretionary decisions (or algorithmic decision) as to whether to buy or sell a stock. More precise slippage calculations could be added to any discretionary or algorithmic decision-processes. Your algorithms for making trades and weighting holdings would improve with time--based on learning from previous results--and would not have to be perfect to begin with.
I think P123 will sort the predicted returns and create a rank although I am not aware that they have confirmed this. I think you will end up using this rank exactly as you have used ranks before if you use P123's upcoming AI/ML alone.
So you are not the first to see that using ranks is not the only way to make buy/sell decisions or that the predictions could be used to determine the weight of holdings:
This is probably already being done by someone using the API as it is a pretty obvious thing to do. I do not know what Pitmaster is actually doing but he obviously thought about using machine learning to determine the weight of his holdings. Now you have have the idea too--as did I and probably many others before us. Maybe Yuval has considered multiple potential uses for predictions (other than replacing ranks)—although they may not include dynamic weighting:
I don't expect to see this with P123's first release of AI/ML I think you will have to continue your research into the API to implement any ideas of using the predicted returns for weighting the holdings in the near future.
But that would NOT BE HARD. You should be able to know the model and hyperparameters of a model you have trained using the P123 AI/ML. You could use this exact same model in Python using data from a download of data using the data download tool and then create predictions of returns with each rebalance using the API. You could use a spreadsheet (or Python) to determine the weights (and even the slippage) of the new purchases. Maybe doing most of it with manual transactions once you have the data and calculations.
Maybe P123 will provide the predicted returns (and maybe a calculation of the slippage at some point) with the rebalances so you that you can skip the need for the API if you want to use machine learning to determine the weight of your holdings (or whether to buy or sell a ticker in the first place).
Assuming that is not a lot more expensive to do rebalance use P123 to rebalance this it is using the API alone to rebalance.
The predicted returns are in memory somewhere (on the processor or on a hard drive) at some point and could, perhaps, be retrieved to be printed with the P123 rebalance—making using the API for dynamic weighting unnecessary . Maybe that is already in the works.