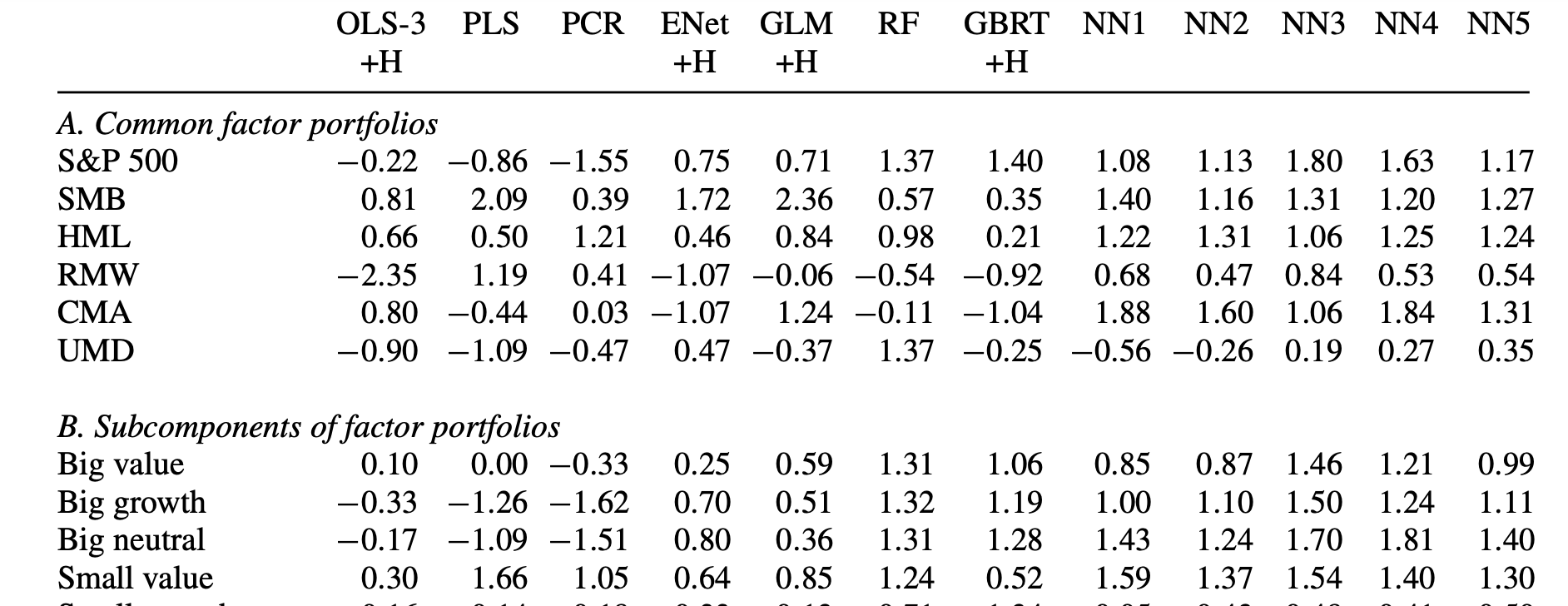
Marco,
As far as how many times they retrained that is the cool thing about AI. Ideally the answer would be infinite (with the fastest computers).
With a MacBook and Python I would do a “GridSearch” for boosting. Here is the code for one of my GridSearches:
parameters = {‘loss’:(‘deviance’,‘exponential’),‘learning_rate’:[.0005,.001,.003,.005,.01,.015,.02,.03,.04,.05,.06],‘n_estimators’:[55,65,75, 100,125,150, 175,200,225,250], ‘max_depth’: [1,2,3, 4, 5, 6, 7, 8, 9]}
For me on that day (with a MacBook) it was 990 iterations (running in a few minutes). So its runs through all combinations of each of those parameters.
That is not to mention the core “Gradient Descent” algorithm that is basically an automated optimization system.
Ideally we would have a quantum computer and the answer would be “we ran through every possibility.” But my guess is the authors had pretty good computers and the answer is “at lot of training (retraining)” and they might not be able to give you a number themselves.
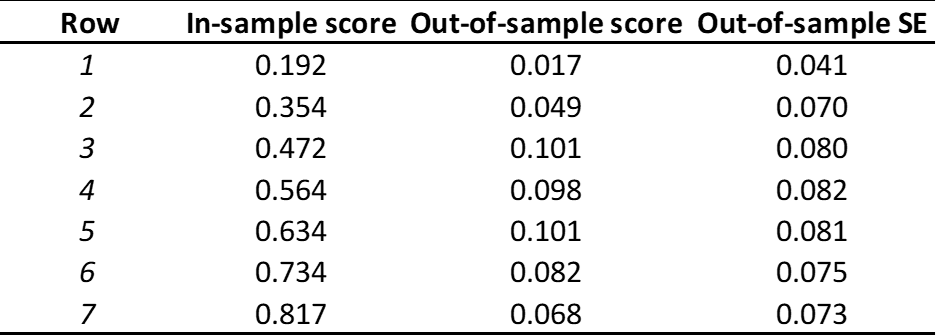
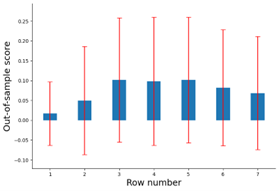
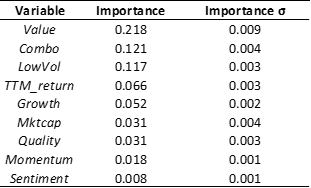
The thing is we already see overfitting with manual optimization at P123. Overfitting when not being able to run through nearly infinite automated iterations.
They control that by training on one set but in some way stopping (eg. early stopping algorithms) or regularizing to get the best results on a different set of data that is not being trained (the validation set).
Then at the end there is the test set which is true out-of-sample where no training or validation was ever done.
There are people at P123 who might disagree in which case we can ignore the authors and start reinventing the wheel with endless debates on the forum. Debates that the Kaggle group will certainly ignore—along the the entire P123 site as a machine learning site. That is not to say they might not use the API and run their own programs with cross-validation.
This does indeed eat up the data. I think 20 years is probably enough for this method, however.
But there are other methods that are better for 20 years of data. The walk-forward method is probably the best but will eat up computer resources.
De Prado like the “purge and embargo method.”
De Prado cautions against the K-fold method (recommending the purge and embargo method to remedy the problems. I have found that he has a point. K-fold has its problems but it is better than allowing pure unchecked overfitting with a computer running unlimited iterations.
Your AI programmer will understand K-fold (if not you should fire her immediately). By now she should be aware of the problems that stock data provides (basically the data is not stationary).
I would recommend kind of a “block walk-forward.” E.g. Train validate 5 years, test the sixth year. Then Train/validate 6 years and test the seventh. Then train/validate 7 years and test the eighth.
With a fast computer your would “walk-forward” each week (not each year).
This ends up being a real backtest of the algorithm that one would be using in real life if possible. One would update the algorithm with an online system like this (each week if possible or perhaps every year).
Maybe your AI specialist may want to discuss his different plans for validation and testing on the forum. Maybe he already has a good plan for this.
She should already have some ideas and be set to implement something in this regard or be willing to explain how she expects people to do this manually.
Jim