Dear All,
This is it! The paper that everyone is quoting for AI based strategies. It is the new benchmark. It’s incredibly complete with many empirical output reports. It must have taken thousands of hours to do (getting a PhD is getting harder and harder).
Empirical Asset Pricing via Machine Learning.pdf (1.1 MB)
Empirical Asset Pricing via Machine Learning Appendix.pdf (570.4 KB)
The paper is also found here
With our impending AI release (‘beta’ before year’s end for sure) it’s time to start a dedicated forum category and kick off discussions. Some key highlights from the paper
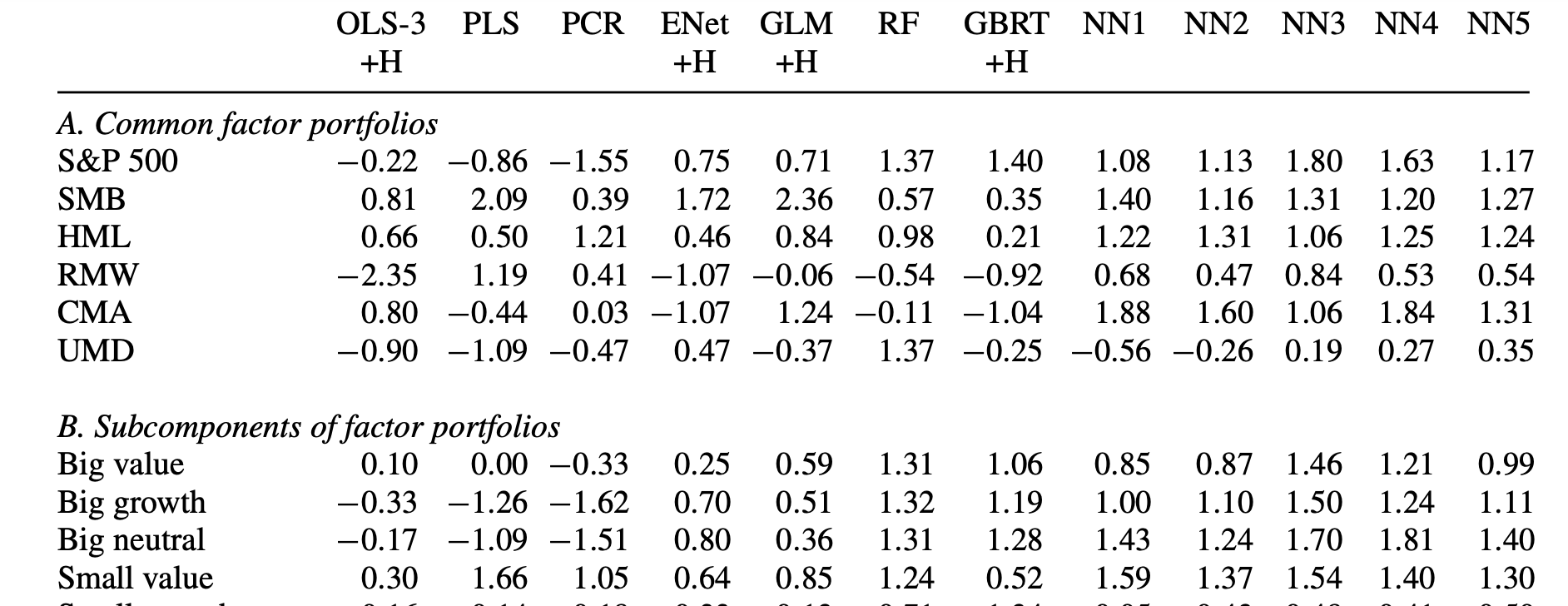
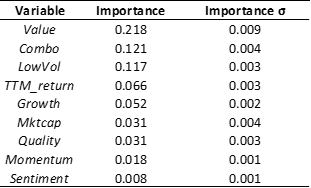
- Top features (a.k.a. predictors , covariates, characteristics, factors) were technical , with top one being the 1mo reversal [1]
- 8 macro series are used. Not clear yet their affect
- Neural Nets came out on top with only 3 layers (in other words should not be too computationally intensive)
- Massive historical dataset (60Y) comes at a price: only annual factors are used with a severe lag (6months+)
One key question raised by this paper is the following: did the technical factors come out on top because of the severe handicaps imposed on the fundamentals (annuals only and 6mo lag) ? Will the P123 shorter history, but less laggy fundamentals, be better overall ?
We are still digesting this paper and modifying our AI implementation accordingly. We should be able to offer all the models they use (NN, random forest, extra tress, etc). We’ll see about other innovations introduced like the use of predictive R2, tuning approach, how features are ranked, performance evaluations (1.8), etc.
In the study 94 features are used; we should be able to recreate most of them. Most require reading additional papers to come up with the formula. Perhaps the P123 community can help? There is always is our Factor Import, but we want to make use of that as very last resort. In other words we want to add missing factors natively if we have the data to create them or approximate them.
That’s all for now. I will pin this post on the new AI category and look for past AI discussion to move here. Please feel free to point them out.
Cheers!
-
the 1Mo return is a reversal factor since it’s inversely proportional as you can see from Figure 7 ↩︎