Marco,
Thank you again for this paper. I assume it is being read at P123 in the context of what P123 will be making available as AI.
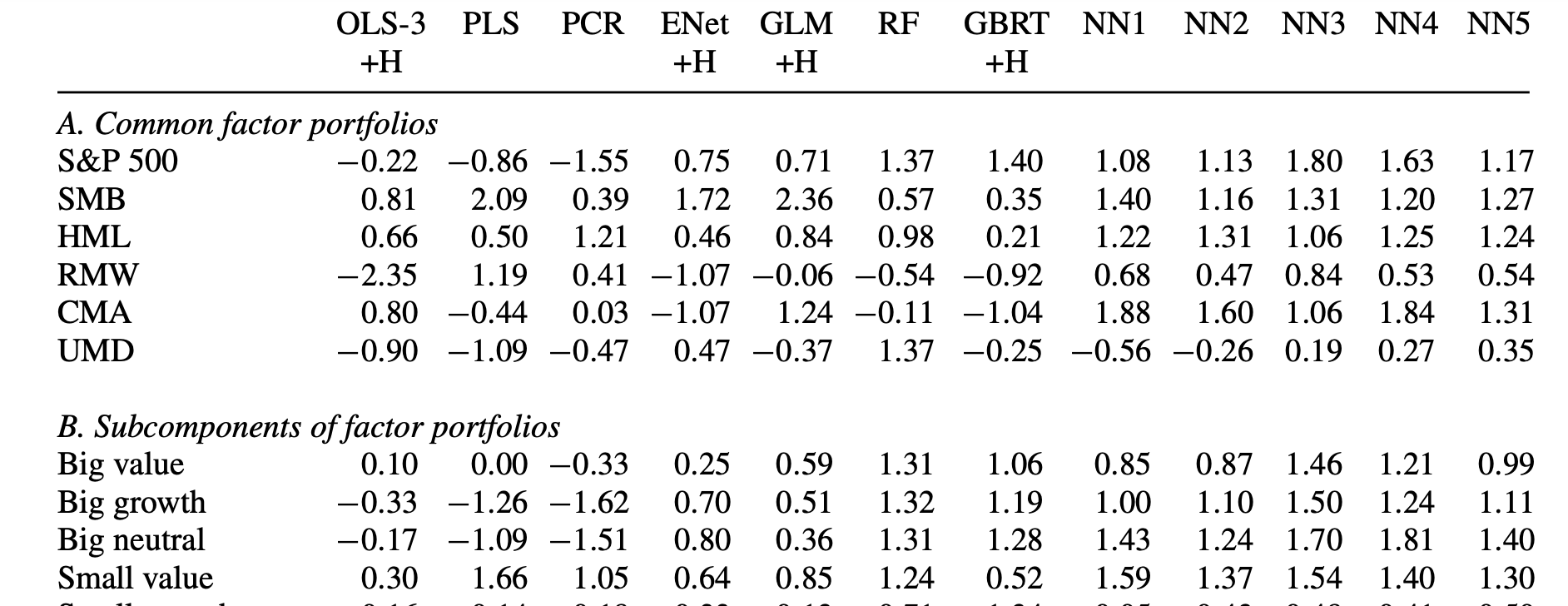
You said: " You can throw the kitchen sink at the problem, the model will sort out the importance."
This is only true in the paper because of the particular method of using training, validation and testing subsamples. From the paper:
" The first, or “training,” subsample is used to estimate the model subject to a specific set of tuning parameter values.
The second, or “validation,” sample is used for tuning the hyperparameters. We construct forecasts for data points in the validation sample based on the estimated model from the training sample. Next, we calculate the objective function based on forecast errors from the validation sample, and iteratively search for hyperparameters that optimize the validation objective (at each step reestimating the model from the training data subject to the prevailing hyperparameter values).
Tuning parameters are chosen from the validation sample taking into account estimated parameters, but the parameters are estimated from the training data alone. The idea of validation is to simulate an out-of-sample test of the model. Hyperparameter tuning amounts to searching for a degree of model complexity that tends to produce reliable out-of-sample performance. The validation sample fits are of course not truly out of sample, because they are used for tuning, which is in turn an input to the estimation. Thus, the third, or “testing,” subsample, which is used for neither estimation nor tuning, is truly out of sample and thus is used to evaluate a method’s predictive performance."
Without this AI at P123 will be just a better way to overfit more than is already being done. It is done in a particular (time ordered) way in the paper because of the time-series nature of stock data—to avoid “data leakage.”
Sometimes this is ignored in machine learning discussions because it is so basic. It is taught in the first few weeks in the freshman year and nothing is done ever again—even at the graduate level—without it. The authors of this paper, however, know how important this is and about the difficulties of doing this correctly with stock data. They did not ignore it.
This is more important than non-linearity or anything else in the paper (if you want to do it right).
It is like assuming there will be air when you are training someone in cross-country running. Not discussed perhaps, but only because it is so basic. It needs to be central to whatever P123 does with AI.
Jim