Two things:
1- I am trying to load my datasets and nothing is happening (seams very slow). I have 3 AI factors that are "waiting" to load...
2- There seam to be a limit of 500 features. I would like to use my own formulas, and I have about 1700 that I would like to use as features. Will the limit be increased?
It's not a server overload. Plenty of servers available, just not the himem ones. We only have three of those , so only use those if you really think you need 160GB . Very few cases will require that much memory.
Here's what's happening:
There's a limit right now of 4 concurrent jobs per user. You had 4 running ones for a long time ( I think single threaded algorithms) so the datasets were not kicking off because of that.
In addition several of your tasks were scheduled on the himem worker so that can be a long wait.
After I cancelled all your waiting tasks and one of the running ones , one of the dataset loads started. The other dataset loads should kick off once one of your running tasks ends. You currently have 1 dataset load, 2 validations, 1 predictor training.
It's very confusing for a user to figure out what's going on. There's no place to see all your jobs whether running or waiting.
We'll try to remedy this tomorrow. Probably start with increasing task concurrency to 6 , better feedback as to what's going on, etc.
PS. Currently there's no way to resubmit a cancelled training tasks. You have to add the model again.
We upped the parallelism to 8 for all beta users , which should help. It still shows 4 in the worker selection popup but you should be able to have 8 running tasks. (it will be fixed when we rebuild)
Also we're making some changes to the UI to clear up the confusion.
We're also studying the allocation of workers to the hardware. Everybody want to to use fastest of course, but if the queue is full you are better off also including workers with less CPUs.
Let us know of UI changes that would make it all clearer.
About the 500 Features limit, will that be increased? I would like to be able to use all my factor formulas (1700), and then select only the factors that are significant (30 to 100). The factors that play no roles in the learning, I would remove.
1700 features should not be a problem. We'll open it up once we have a more scalable system.
Also, we are missing the tools to find insignificant features. We're still planning these tools. How were you going to classify the factors in order of significance?
No easy answer to find the features signigicance, as its going to be different for each models. Some are easier to implement, and other (such as the NN), so as easy:
Extra Trees: Utilize built-in feature importance scores.
DeepTablesNN: Apply permutation feature importance for analysis.
GAM: Analyze feature significance through coefficient analysis.
KerasNN: Use permutation feature importance or SHAP values.
Linear Models: Rely on coefficient analysis and p-values.
Random Forest: Leverage built-in feature importance scores.
Great list of models and importance techniques. The challenge is to design a cohesive, easy interface that works with what we have.
The original Gu paper that committed us to adding ML to P123 used two different techniques (both produced similar results), and they call it Variable Importance.
In short they iterate trough each feature, manipulate the feature (like setting it to 0), and for each training period calculate some statistic (like reduction in R2) and rank the results.
It's a nice technique that can be used for any model. But it can take a while to compute, depending on the model. For example if you have 500 features and your model validation took 10 minutes, it would run for 3.5 days to calculate Variable Importance for that model alone. But if the model only took 1 min then it's a much more reasonable 8 hours.
Of course the built-in feature importance of some algorithms costs nothing. We just have to display it somehow.
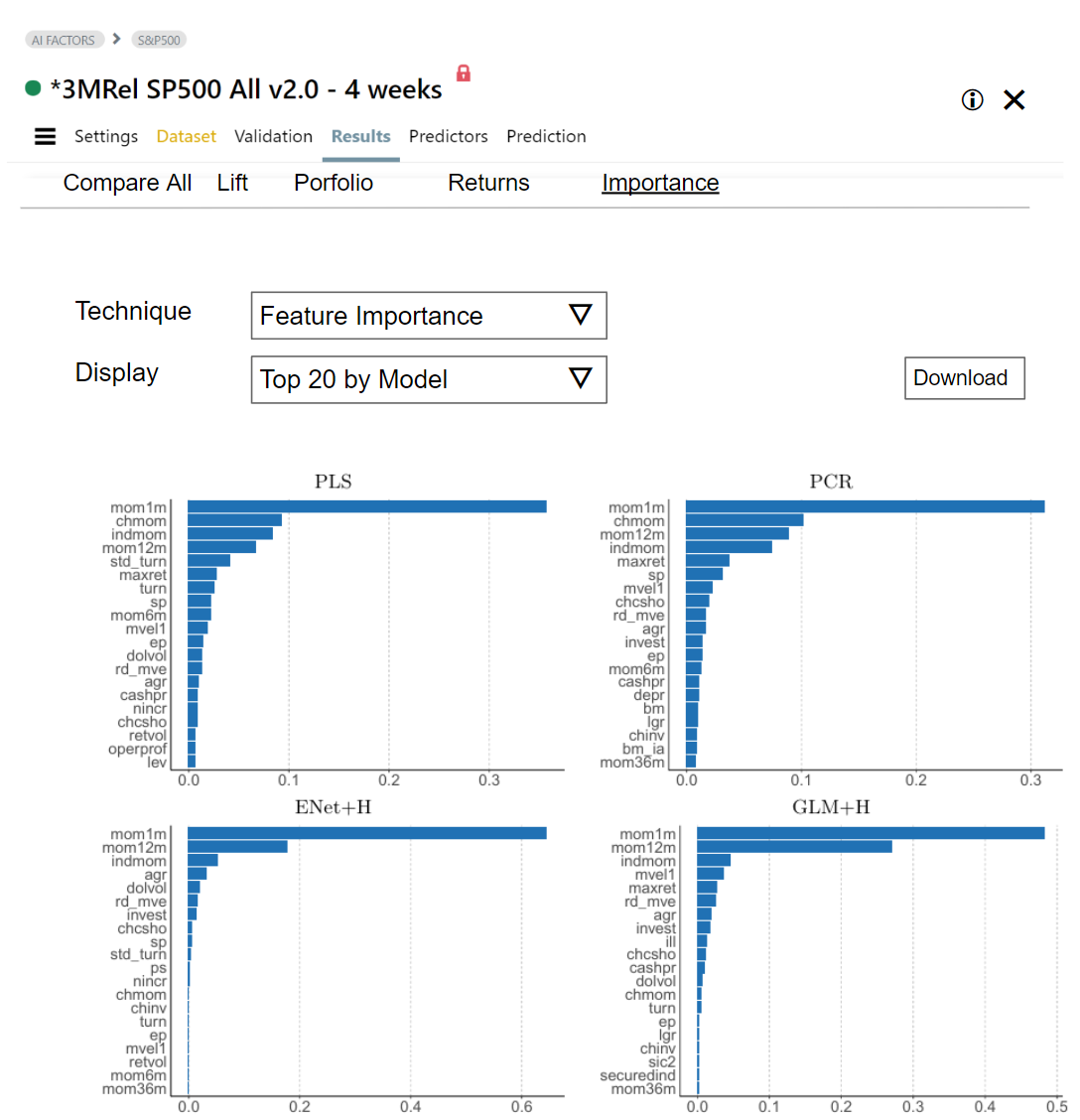
I think we got enough to start putting down some designs. Probably just add a new "Importance" page in the Results where you will be able to see the different kinds of importances that are available, whether built in, or that you have calculated.
Something like this. What do you think? Only what's available will be displayed, and different techniques could have different displays. I borrowed the image from the paper that has features listed on the left and model name on top of each chart.
LASSO regression is designed to remove features with little significance. Some would do a LASSO regression, remove the features that did not make it with the LASSO regression, then run a Ridge Regression with the features that remain (after LASSO regression) for predictions.
We have that option now or the retained features could be exposed if not already done. I have not done a LASSO regression with P123's AI to know.
Elastic net regression combines LASSO and Ridge regression into one regression. Removing some features and regularizing the remaining features in one step with 2 hyperparameters that can be adjusted with cross-validation.
I am not arguing for a particular method. But the time estimate for something like Permutation feature importance is much less than your above estimate.
This is because this method changes only the validation data (shuffling or randomizing a feature within the validation set only). The training set is never retrained. There is no retraining to be included in the calculation of how long this would take.
So for models with quick prediction times but long training times this might be a viable method for your consideration.
I don't have a strong preference on what you end up doing. I understand you may end up deciding on more than one method and that you will make a well-reasoned choice based on a lot of priorities including use of computer resources.
But this does have he advantage that: "It's a nice technique that can be used for any model" as you correctly point out. And this might mean the option of having feature importances for say, support vector machines or neural-nets, with an extremely long training time. For models that, otherwise, would not have the option of variable importances in other words.
And it is a method that can be consistently applied across different types of models, allowing for standardized comparisons of feature importance.
TL;DR: Permutation feature importance can be much faster than methods that require retraining and is commonly used because of this advantage.
-Tested for accuracy with Claude 3 Sonnet and ChatGPT 4o. Claude 3 Sonnet did not change my ideas or wording on this topic much (and was just happy ChatGPT did not find any factual errors). I am considering using this method (and others) myself and thought it expanded on the excellent discussion above.
That would indeed be a lot faster. But the paper in section "2.3 Which covariates matter?" says
"To begin, for each method, we calculate the reduction in R2 from setting all values of a given predictor to zero within each training sample, and averagethese into a single importance measure for each predictor."
Since they talk about setting to zero in the training sample doesn't that imply retraining?
"Permutation importances can be computed either on the training set or on a held-out testing or validation set. Using a held-out set makes it possible to highlight which features contribute the most to the generalization power of the inspected model. Features that are important on the training set but not on the held-out set might cause the model to overfit."
This supports a shortened statement: "To prevent overfitting, it is generally recognized that using permutation importance in a hold-out test set or validation set is preferable and good practice."
I do not even begin to think this short post is the final word on this complex subject. But permutation importance is less resource intensive when used on the validation set and I think there is general consensus that it is better for preventing overfitting when used on the validation or hold-out test set (as quoted above).
TL;DR: Permutation importance is less resource intensive than the paper you site. While none of this is definitive, it is not immediately clear permutation importance is not equally good or maybe better if addressing the problem of overfitting is a priority.
Jim
Accuracy checked with Claude 3 Sonnet and ChatGPT 4o. I welcome any further corrections.
I am interested in this myself. I went ahead and timed this for what is essential one fold in a k-fold cross-validation with about 30 features. I though the results could be interesting to you too:
Note that I used: result = permutation_importance(model, X_val, y_val, n_repeats=1, random_state=42, n_jobs=-1). There is the option to repeat the permutation importance multiple times and average multiple results by changing the hyperparameter n_repeats. So more time if this is increased.
The results for permutation importances made sense to me but no guarantee it was optimal based on my impression alone.