Great list of models and importance techniques. The challenge is to design a cohesive, easy interface that works with what we have.
The original Gu paper that committed us to adding ML to P123 used two different techniques (both produced similar results), and they call it Variable Importance.
In short they iterate trough each feature, manipulate the feature (like setting it to 0), and for each training period calculate some statistic (like reduction in R2) and rank the results.
It's a nice technique that can be used for any model. But it can take a while to compute, depending on the model. For example if you have 500 features and your model validation took 10 minutes, it would run for 3.5 days to calculate Variable Importance for that model alone. But if the model only took 1 min then it's a much more reasonable 8 hours.
Of course the built-in feature importance of some algorithms costs nothing. We just have to display it somehow.
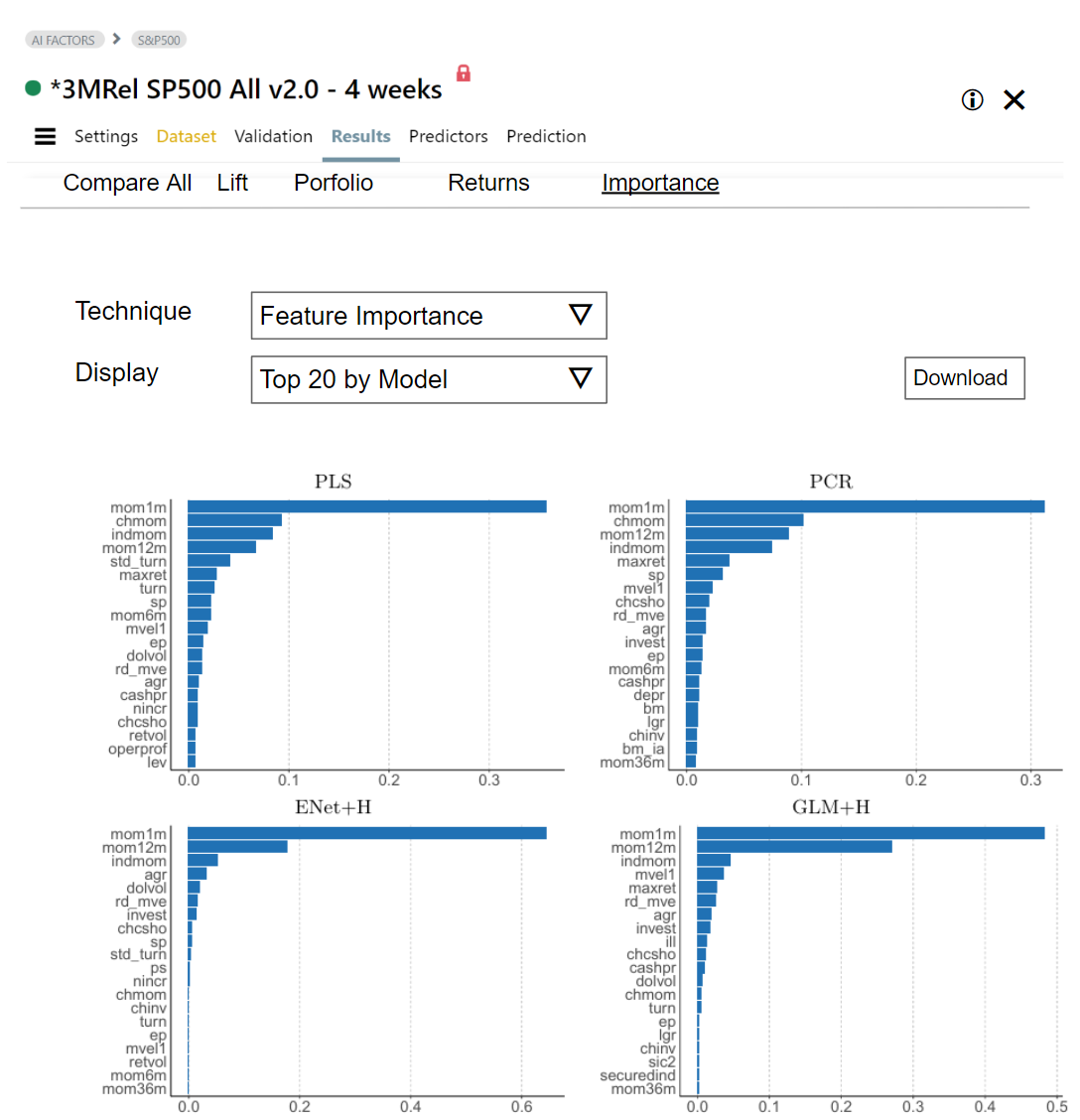
I think we got enough to start putting down some designs. Probably just add a new "Importance" page in the Results where you will be able to see the different kinds of importances that are available, whether built in, or that you have calculated.
Something like this. What do you think? Only what's available will be displayed, and different techniques could have different displays. I borrowed the image from the paper that has features listed on the left and model name on top of each chart.
Thanks