Judge and VS,
I saw these posts on X.
It seems both of you are doing better than the quant hedge funds YTD 2026 mentioned in the latest Bloomberg article below.
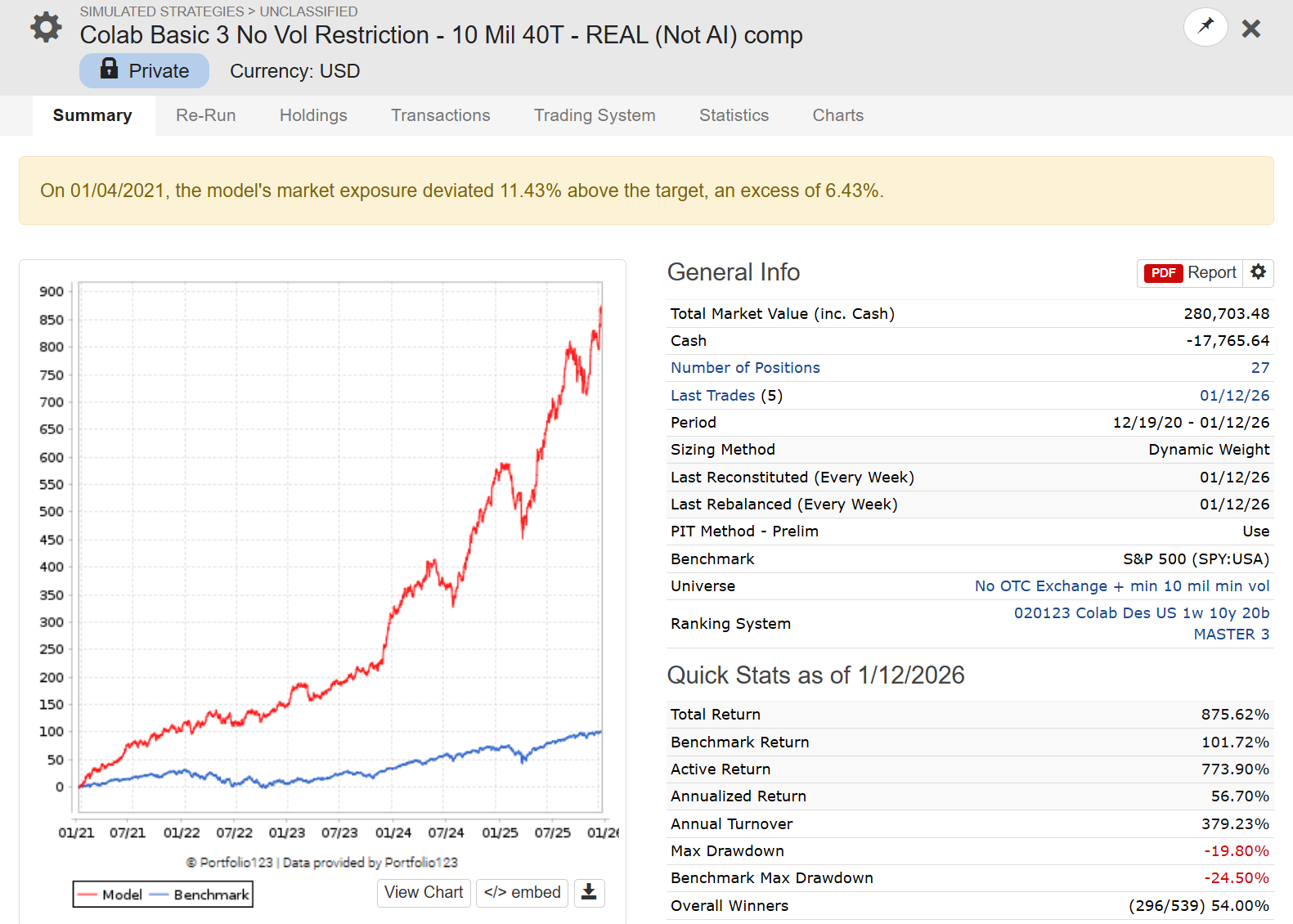
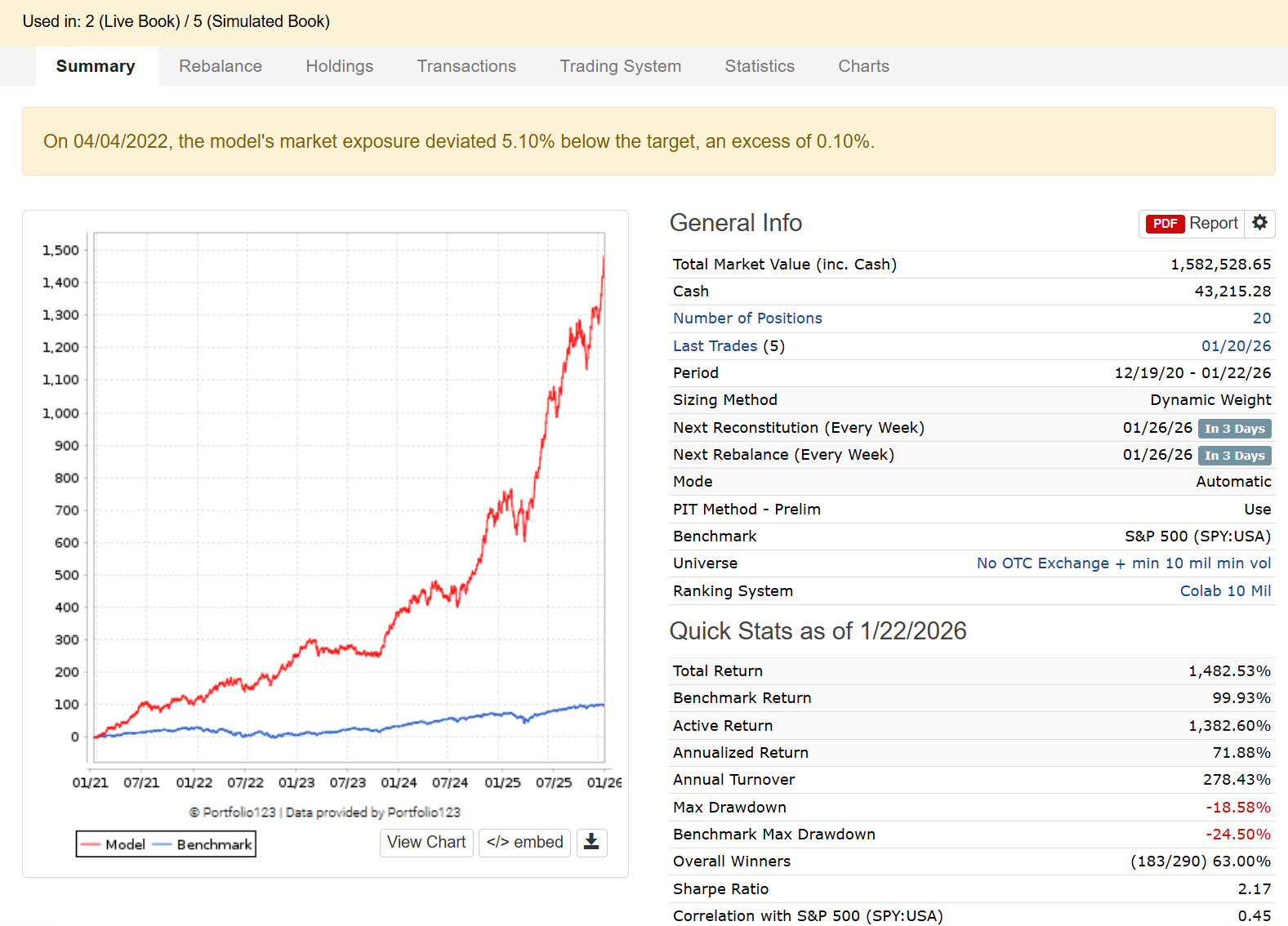
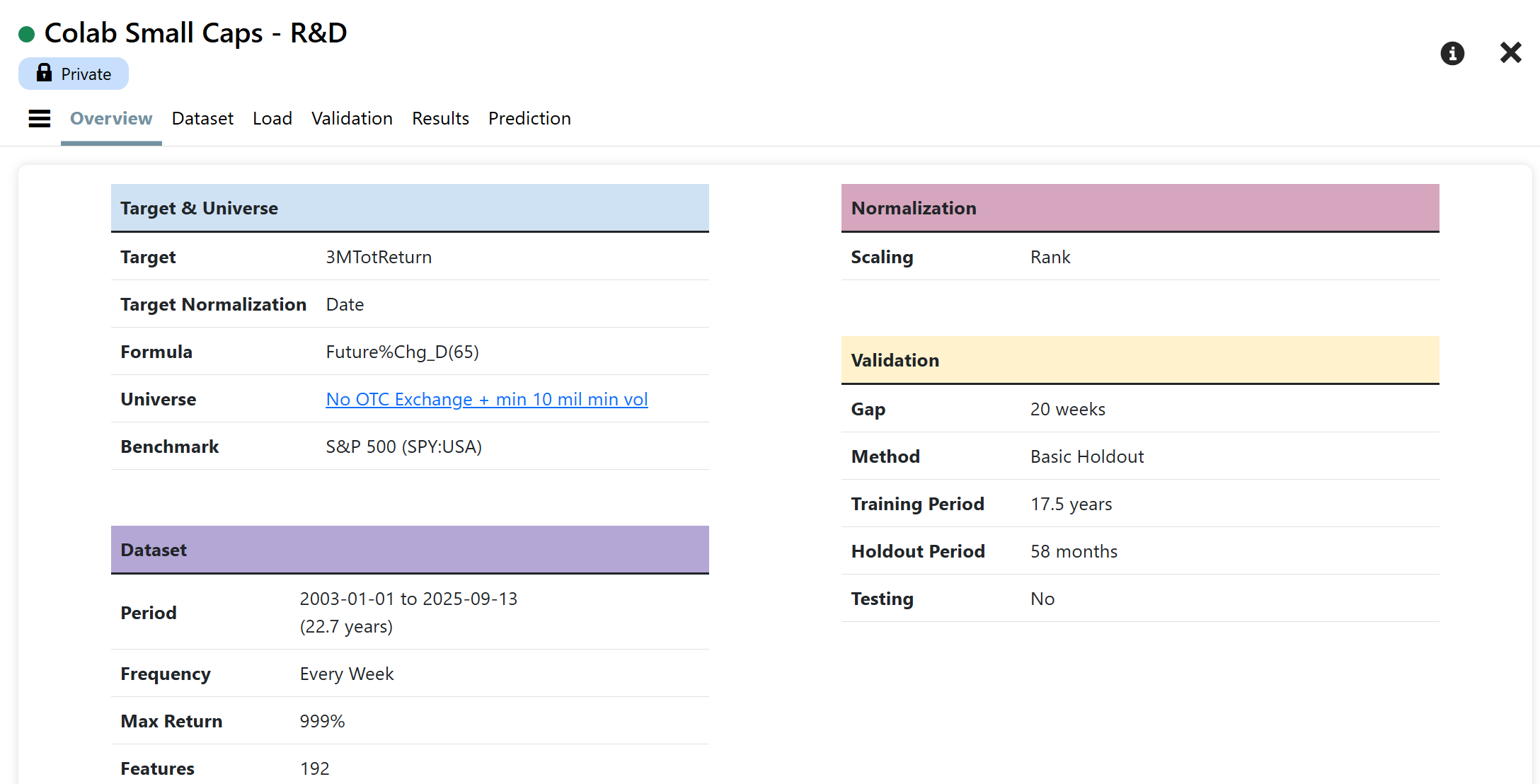
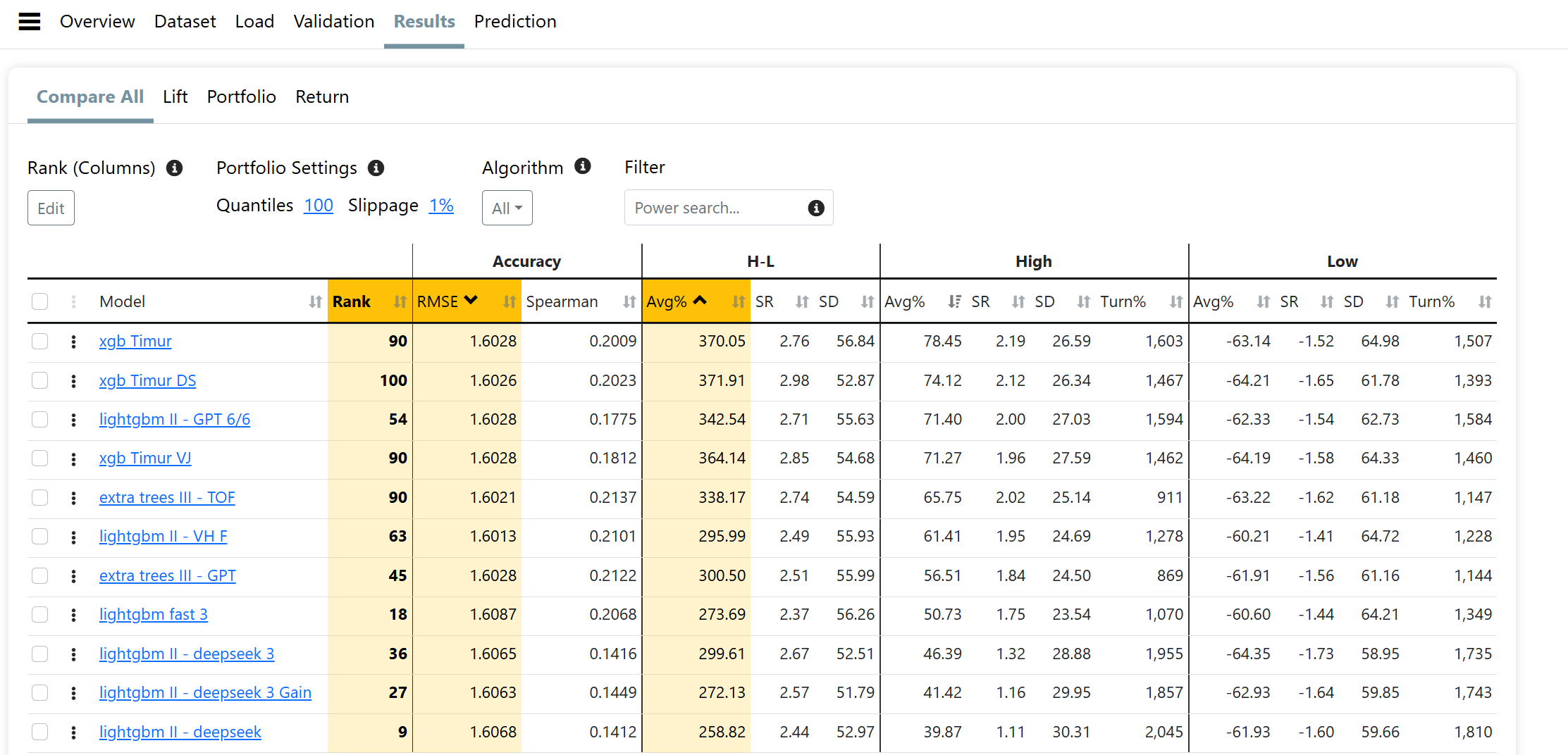
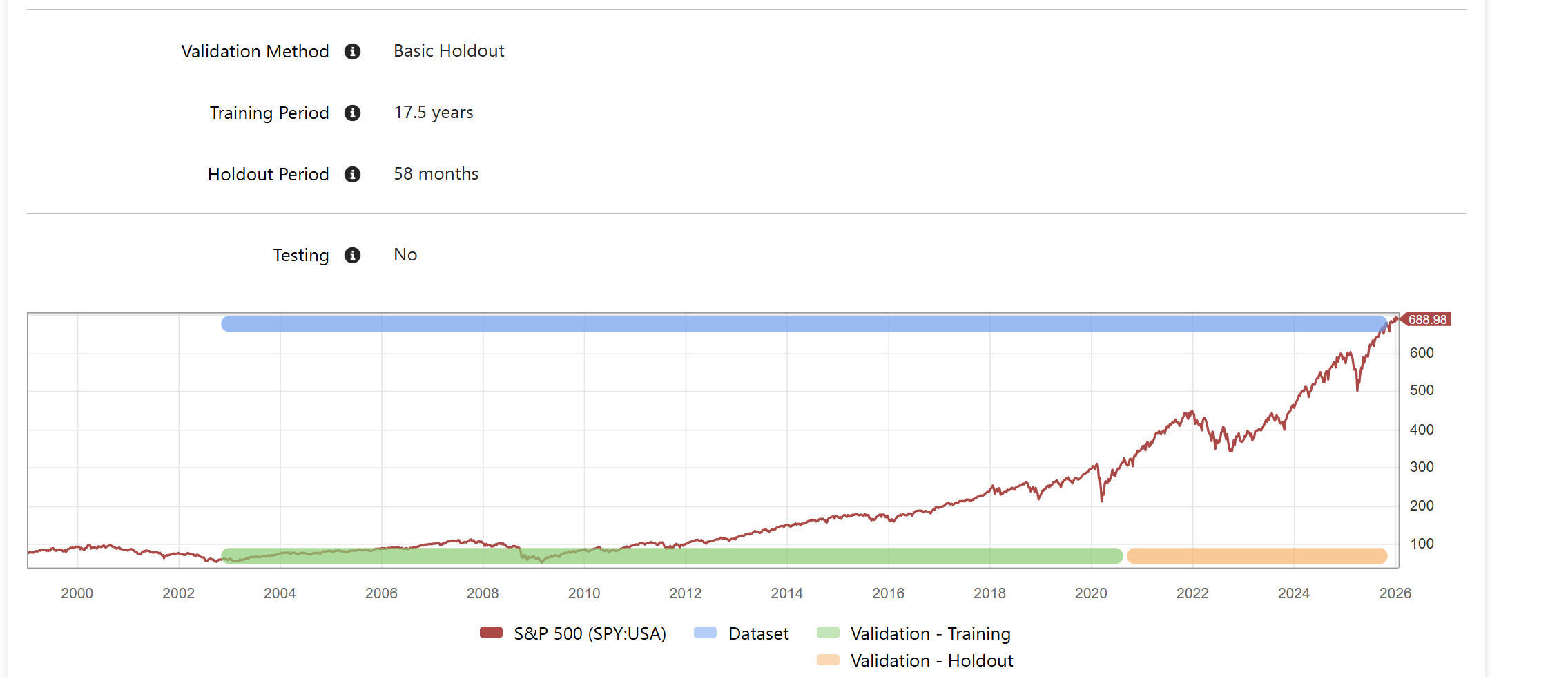
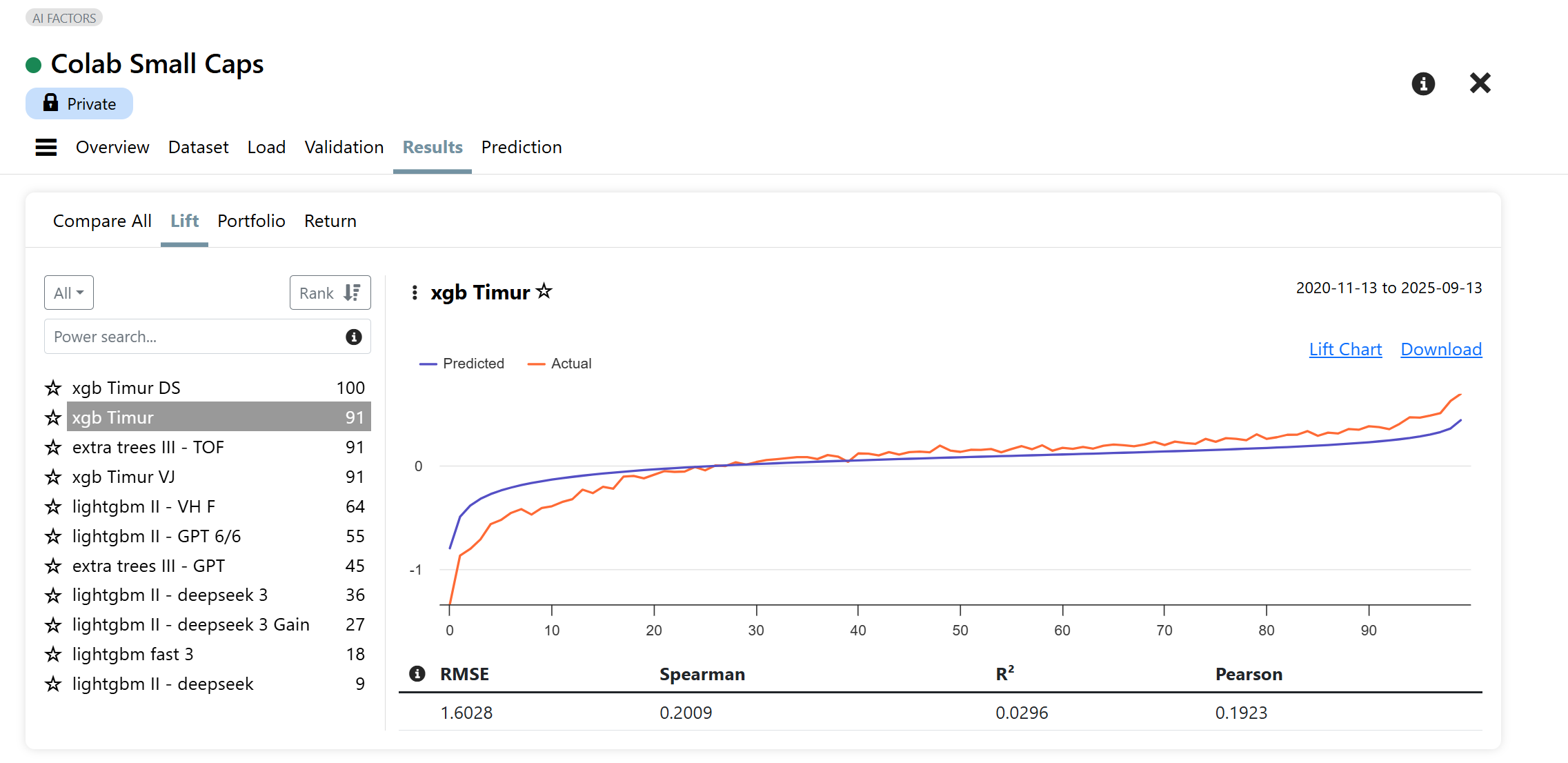
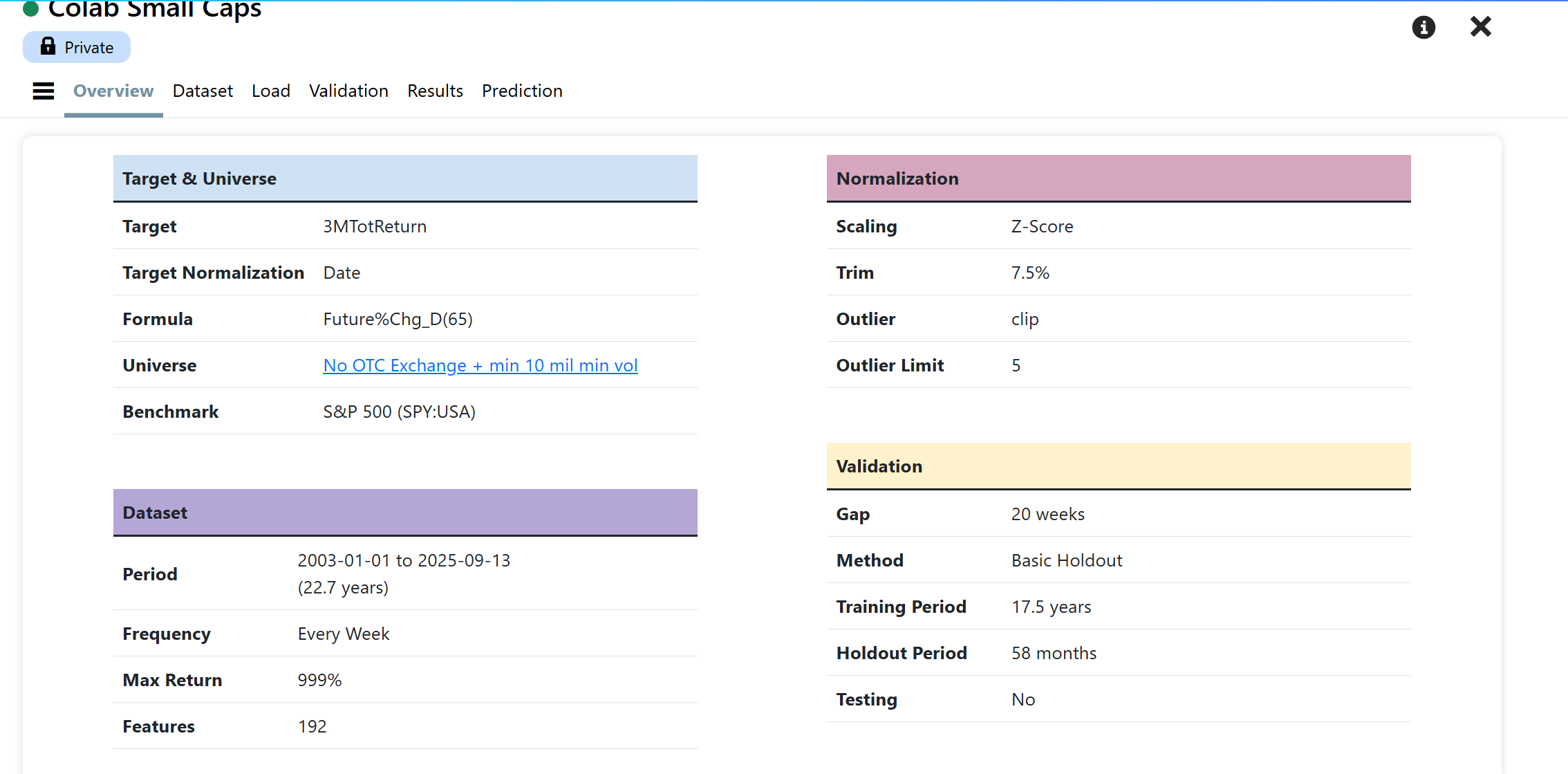
Can you share some more info about the P123 AI factor strategies and whether it is possible to subscribe to these? Based on the screenshots, it seems possible for P123 AIfactor to beat the best quant hedge funds (at least in the past 2 weeks.)
Thank you for sharing in advance.
Regards
James
Judge
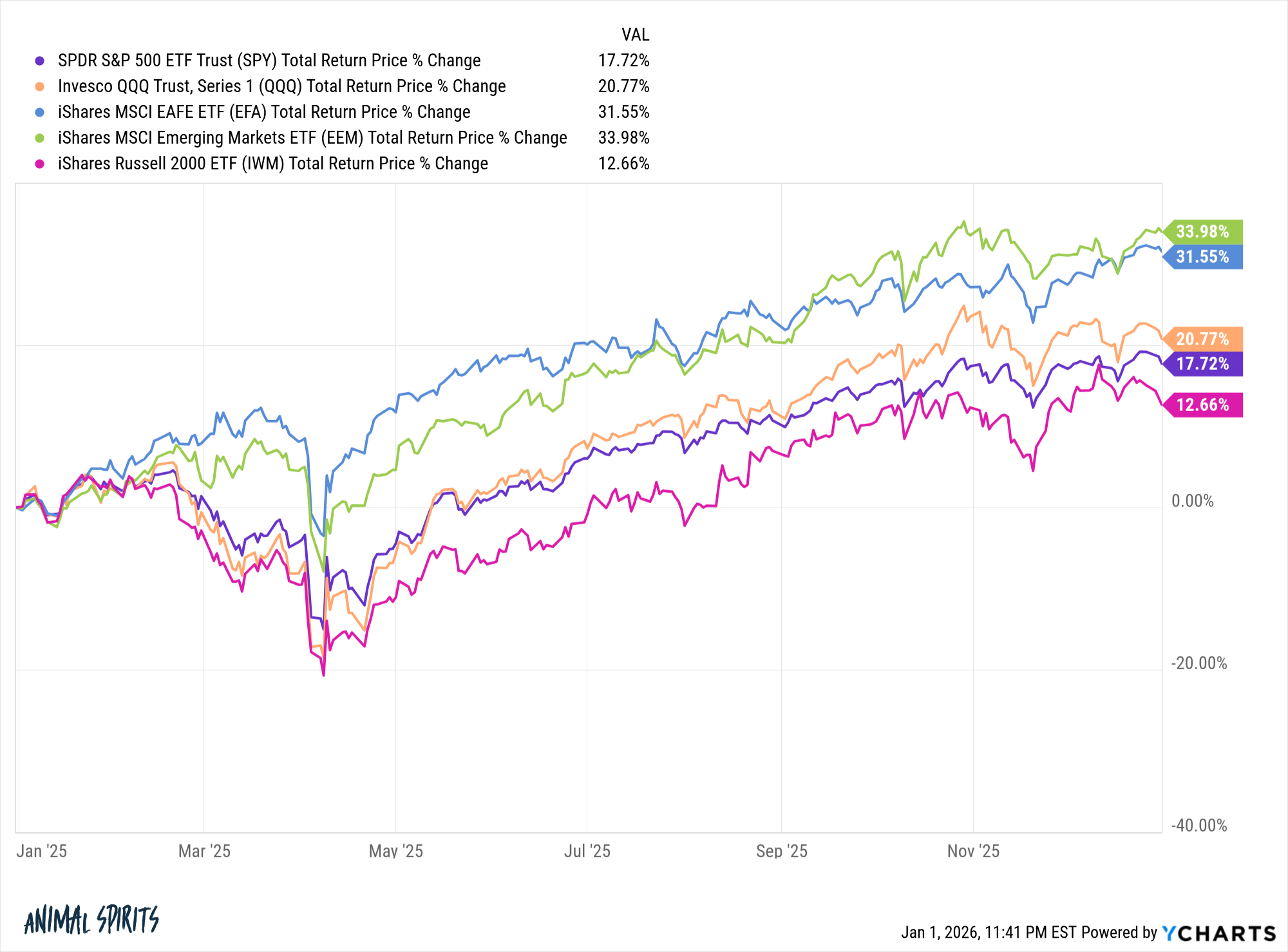
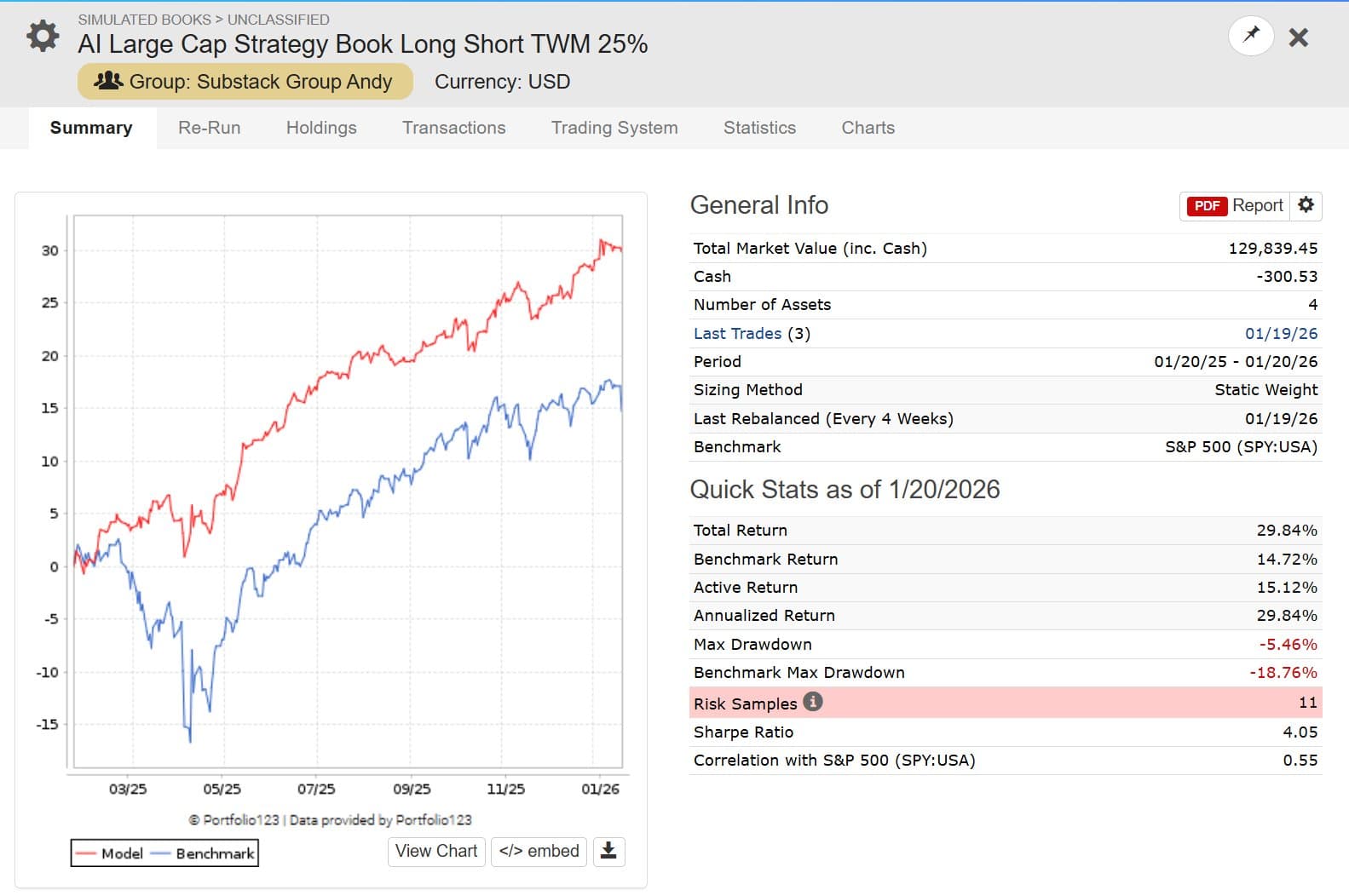
My Long/Short (Substack: Systematic AI Investing Portfolios, see my profile) book is holding up well: Long AI Factor S&P 500 models, hedged with a hefty 25% short on the Russell 2000 (TWM). This is working even as IWM shows strength right now.
VS
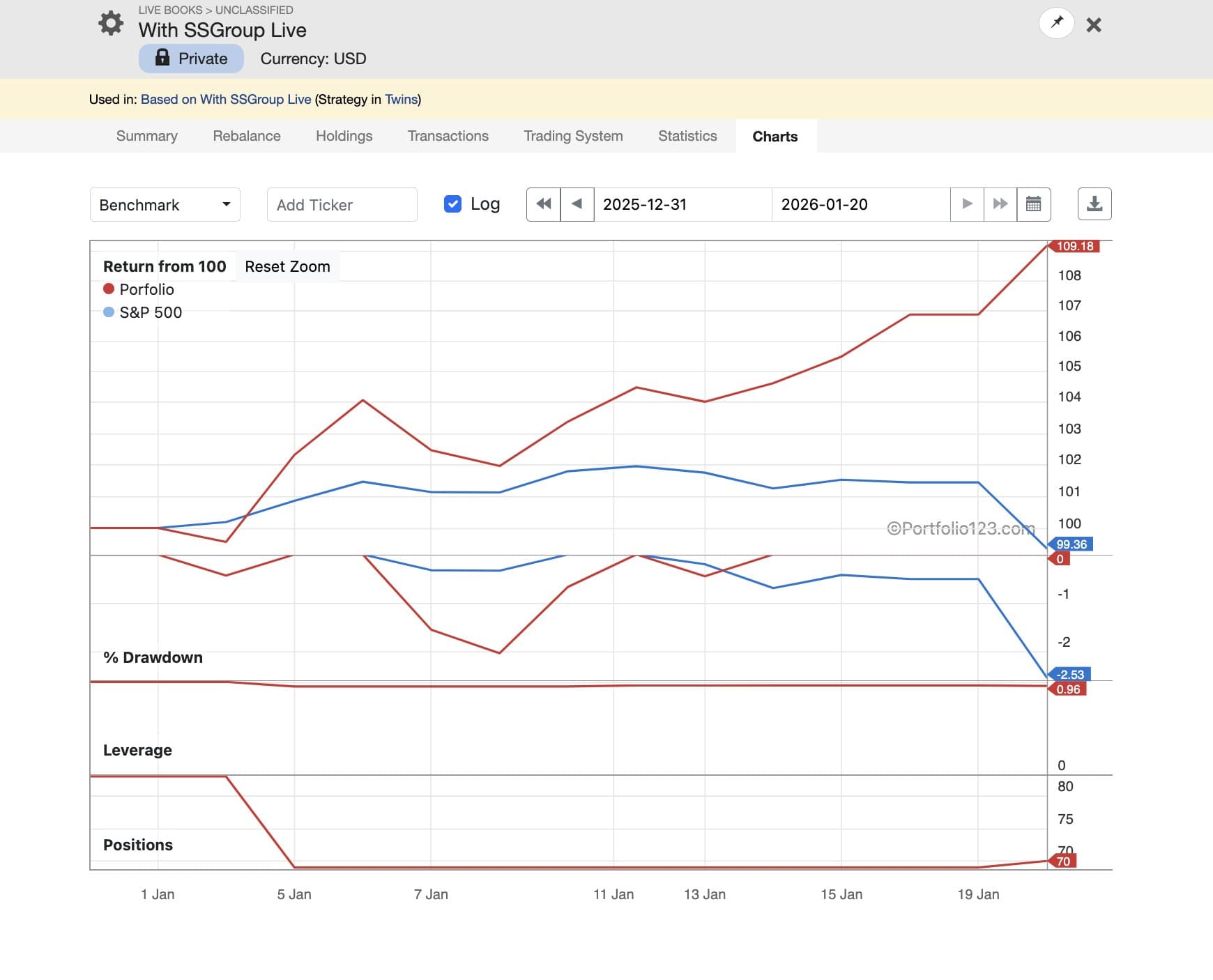
One exciting part of strategy development is knowing when to push the pedal and then seeing the pedal push paid off. On new years I deployed a set of changes to my @P123Finance to better align with my utility function. The resulting changes = 50% > YTD 2026 returns.
Quants in Worst Losses Since October as Crowded Bets Buckle
By Justina Lee
January 21, 2026 at 9:11 PM GMT+8
Updated on
January 22, 2026 at 12:19 AM GMT+8
Takeaways by Bloomberg AI
-
Quant hedge funds are off to a poor start in 2026 due to setbacks in US stocks, with losses reaching 1% in the first 10 days of January.
-
The losses were concentrated in US equities, with US quants estimated to have lost 2.8% over the first two weeks of 2026, according to UBS Group AG.
-
The recent selloff stemmed from factors including losses in crowded positions, short positions on high-beta names, and adverse idiosyncratic moves, according to Goldman Sachs.
Quant hedge funds are kicking off the year in the red, as setbacks in crowded US stocks clobbered the strategies, reviving concerns about volatile returns in the sector.
Early January marked the worst 10-day period for systematic long-short equity managers since October, with losses reaching 1%, according to prime brokerage data from Goldman Sachs Group Inc. Most of the pain was concentrated in US equities, Goldman’s Kartik Singhal and Marco Laicini wrote in a note, drawing parallels with the sharp drops that hurt quant portfolios in June and July last year.
Losses at US quants amounted to 2.8% over the first two weeks of 2026, UBS Group AG estimated, based on its prime book. It noted that Friday had seen the sharpest one-day deleveraging since Dec. 22.
Market moves spurred by US policies this week may have taken some pressure off, but the damage has already been done. It remains to be seen whether systematic hedge funds will be able to claw back some gains.
Many quant funds ended 2025 in the black. However, they endured two violent loss-making periods, the first in early summer and then in October, when they were tripped up by reversals in momentum, coupled with a junk rally. Similarly, the most recent selloff stemmed from three main factors, according to Goldman: losses in crowded positions, short positions on high-beta names, and adverse idiosyncratic moves.
“The idiosyncratic drag has been driven predominantly by the short book, similar to the June-July drawdown,” Singhal and Laicini told clients, adding that this time momentum strategies helped cushion the blow.
Quants’ poor start to 2026 coincides with volatility on world markets. While AI and economic confidence fueled a rotation into riskier shares and small-caps when the year began, risk sentiment soured early this week amid President Donald Trump’s insistence on taking control of Greenland and renewed trade-war fears.
Since computer-based hedge funds typically rely on a variety of proprietary trading signals, it’s hard to pinpoint the exact source of the losses. Analysts taking a bird’s eye view often dissect performance based on so-called factors, effectively, stock characteristics documented by academia to drive returns.
The three episodes of pain, including the one this month, have one thing in common: a rally in so-called junk assets that saw riskier, more volatile shares surge. Such episodes tend to hit quants that typically short such low-quality companies.
“Although many quants try to be ‘factor neutral,’ it’s not easy to be completely factor neutral, especially when factors have significant moves,” Yin Luo, a quant analyst at Wolfe Research LLC, said in emailed comments. “Year-to-date, most factors are in the ‘wrong’ direction.”
Tuesday’s drastic risk-off shift might have helped ease the pain, added Luo, who noted that long bets popular among hedge funds rose, while heavily shorted names fell.
But even after taking into account those gains Tuesday, a strategy that goes long steadier shares and short the opposite has lost about 4.3% so far this year, while the ‘quality’ trade that favors more profitable, less leveraged stocks has dropped around 0.8%, S&P Dow Jones indexes based on US stocks show.
Global stock markets recovered Wednesday after Trump said the US doesn’t want to use excessive force to get Greenland.
“When you go from 0 to down 5 in the first couple weeks of the year, you’re getting a call from the risk manager, and it’s not to wish you a Happy New Year,” said Blago Baychev, co-founder of PharVision Advisers, a systematic equity hedge fund. “Crowding, both on the long and the short side, is the ever-elusive risk factor that everyone is trying to either hedge or dodge, but it is getting increasingly difficult.”
(Updates market moves throughout, adds Wednesday market context in penultimate paragraph and manager comment in last paragraph)