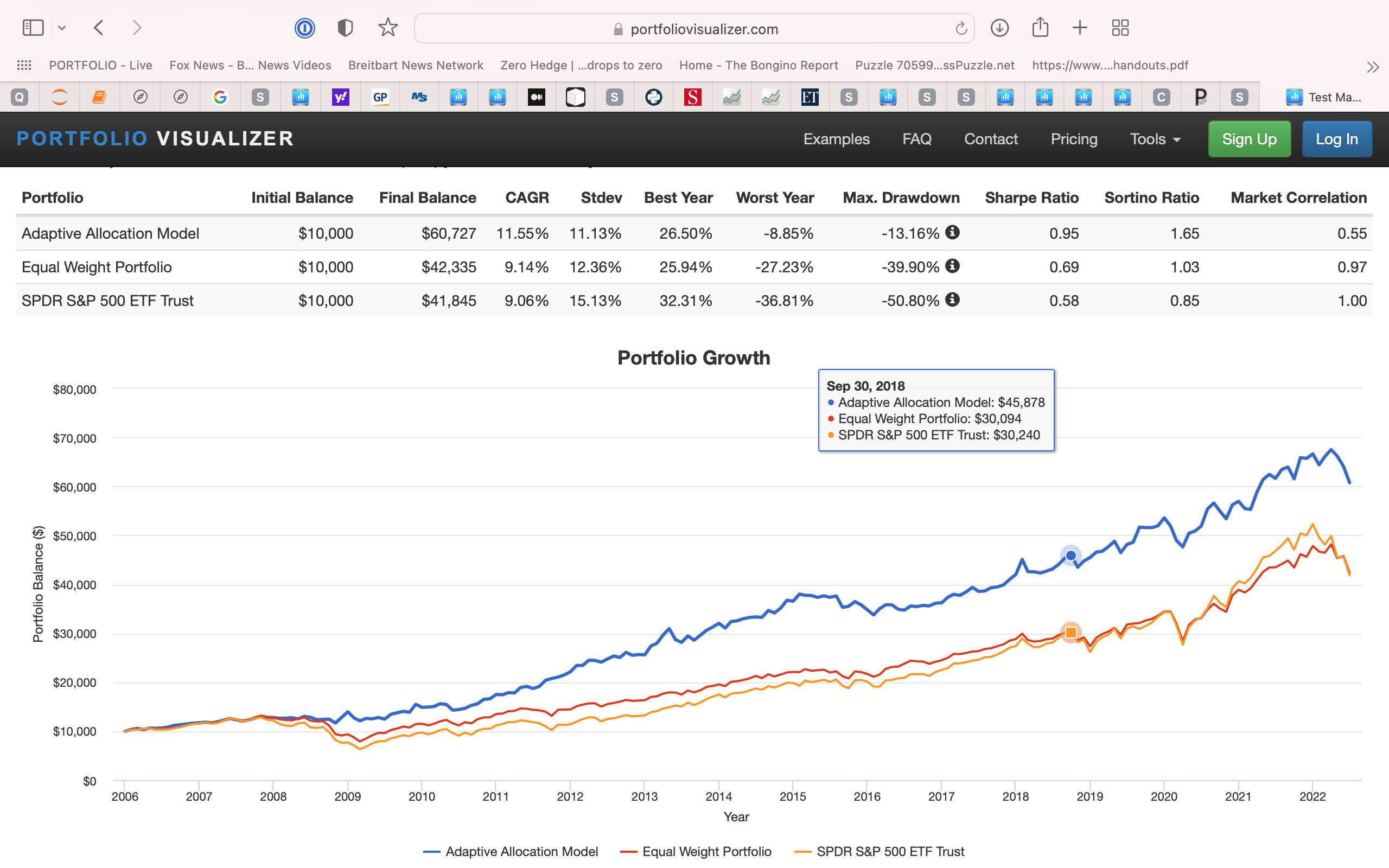
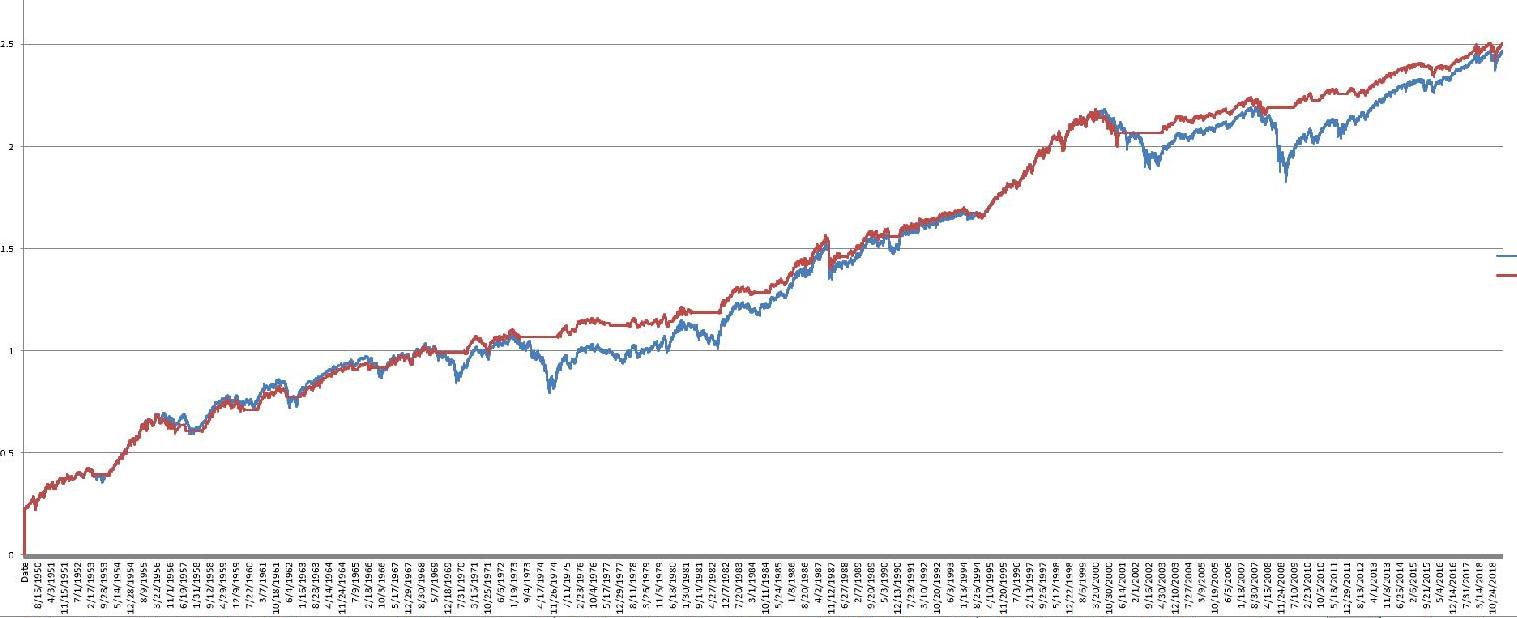
Once you’ve settled on a fundamental strategy, the fundamentals don’t tell you to much on when to buy the stock. To better plan the buy, I have frequently utilized ROC (40) in the grading system to acquire stocks that have recently fallen.
What are your experiences with technical analysis? Which indicators have produced statistically significant enough results to provide a value in an equity strategy?
There does not appear to be much in the academic literature that supports the use of technical analysis:
https://stocksoftresearch.com/technical-analysis-for-stocks/
https://www.cxoadvisory.com/technical-trading/technical-analysis-tested-globally/
https://www.cxoadvisory.com/commodity-futures/performance-of-technical-trading-rules-for-crude-oil-futures/
https://www.cxoadvisory.com/technical-trading/technical-analysis-as-a-mutual-fund-discriminator/
https://www.cxoadvisory.com/individual-investing/individual-investor-performance-by-motive-and-method/
https://www.cxoadvisory.com/technical-trading/technical-analysis-tested-on-long-run-djia-data/
https://www.cxoadvisory.com/technical-trading/updated-comprehensive-long-term-test-of-technical-currency-trading/
https://www.cxoadvisory.com/technical-trading/true-out-of-sample-test-of-best-technical-trading-rules/
https://www.cxoadvisory.com/investing-expertise/evaluating-5017-technical-trading-recommendations/
https://www.cxoadvisory.com/technical-trading/technical-trading-thoroughly-tested/
https://www.cxoadvisory.com/technical-trading/technical-indicator-model-of-stock-returns/
https://www.cxoadvisory.com/technical-trading/moving-average-rules-over-the-long-run/
https://www.cxoadvisory.com/technical-trading/taking-the-noise-out-of-technical-trading/
https://www.cxoadvisory.com/technical-trading/testing-the-indicators-of-barchart-com/
https://www.cxoadvisory.com/individual-investing/technical-analysis-a-drag/
https://www.cxoadvisory.com/technical-trading/technical-trading-rules-and-data-snooping-bias/
https://www.cxoadvisory.com/technical-trading/testing-the-head-and-shoulders-pattern/
https://www.cxoadvisory.com/technical-trading/bollinger-bands-buy-low-and-sell-high/
https://www.cxoadvisory.com/technical-trading/combining-rsi-and-macd-in-search-of-concentrated-abnormal-returns/
https://www.cxoadvisory.com/technical-trading/simple-test-of-macd-crossover-as-an-abnormal-returns-indicator/
https://www.cxoadvisory.com/technical-trading/classic-papers-returns-from-pattern-based-technical-analysis/
https://www.cxoadvisory.com/technical-trading/technical-analysis-of-market-bubbles-and-anti-bubbles/
https://www.cxoadvisory.com/volatility-effects/testing-a-complex-breakout-indicator/
https://www.cxoadvisory.com/technical-trading/trading-after-n-day-highs-and-lows/
https://www.cxoadvisory.com/volatility-effects/does-a-long-term-moving-average-indicator-predict-big-days/
https://www.cxoadvisory.com/technical-trading/simple-test-of-rsi-as-an-abnormal-returns-indicator/
https://www.cxoadvisory.com/technical-trading/unexplained-volume-as-a-critical-indicator/
https://www.cxoadvisory.com/technical-trading/does-technical-trading-work-with-commodity-futures/
https://www.cxoadvisory.com/technical-trading/out-of-sample-tests-of-bullish-regime-2-day-rsi-signals/
https://www.cxoadvisory.com/technical-trading/candlesticks-fiddlesticks/