So the Russell 2000 is really doing poorly. If we go back 10-12 years it is obvious it has not outperformed the S&P 500 despite being more risky.
Maybe the small cap premium “disappeared” just like value and momentum. Strange huh?
The so-called “small cap effect” isn’t and never was a real thing.
Statisticians (Fama French and their many followers over the years) at one time observed that small caps outperformed (obviously, whether that’s true or not depends on the time period(s) observed) but as they often do, they never went further to try to understand why they saw what they thought they saw.
Small companies are inherently different from large companies in two important ways. (1) They tend to suffer from dis-economies of scale, or in accounting terms, fixed costs tend to consume a greater portion of revenues. That makes for increasing earnings volatility as sales fluctuate. i.e. more investment risk. (2) They tend to be less internally diversified, if not in industry exposure, then even within a single industry, diversified in terms of the kinds of products they make, the kinds of services they offer, the kids of customers they have etc. That, too, increases volatility much the way a five-stock portfolio will usually be more volatile than a 50 stock portfolio.i.e. more investment risk.
So really, company (and stock issue) size is part and parcel of the overall quality-low vol factor.
Many of the studies that purported to document a small cap effect covered sample periods during which bullish conditions predominated and during which investors were tolerant of – or eager for – more risk. During portfolio123’s early days, the Fed was printing money like it was going out of style and shoving it into the capital markets, meaning there was a surplus of equity capital and that, naturally, favored the lowest quality capital users (the small, micro, sub-micro and insanely micro cap stocks) and caused models to succeed with such factors as MktCap (smaller is better) and SalesTTM (smaller is better).
Lately, though, attitudes toward risk and pump priming have been more variable and small cap performance has been pretty much in line with what one would expect of a higher-risk portion of the market.
So yes, I agree there is no small cap premium – never was, isn’t now, and never will be. But attitudes toward risk do change and small size can be a handy thing to favor or avoid depending on how you want to play the risk-on versus risk-off phenomenon.
While the broad average return of small-cap shows no premium, that is not to say there is no opportunity here. I am still able to find persistent alpha in micro- to small-caps. I am not able to find it in large- to mega-caps. There is a wide dispersion of returns in smallcaps and using the tools provided by P123, there is still strong and persistent alpha in this universe.
Large portfolios of 100 - 300 smallcap stocks can still be constructed based on 5 to 10 academically sound factors with annual out-performance every year since 1999.
So yes, a cap-weighted average of all small stocks will definitely hide this alpha among higher risk and lower returning stocks.
Wow! That’s impressive. Could you share the plot of that portfolio’s equity curve?
Walter
I heartily agree with the first and third paragraphs.
But I think it would be somewhat hard to construct a small cap system with such a large number of stocks and based on so few factors that would actually beat the S&P 500 every single calendar year. In some years–particularly 1999, 2008, and 2018–SPY just walloped small caps.
I realize that my predisposition to defend the academic canon on EMH puts me at odds with many here, but I wanted to share some historical context…
Markowitz’s work on MPT was based on an intuition that expected market returns were based on risk premia. Indeed, returns used to be correlated with market Beta prior to his work, but that relationship switched directions as high beta securities became over-crowded.
Everyone wants to dump on Fama-French factors for not being sophisticated enough, but they were never intended for stock picking in the first place. Rather, they simply meant to show that an efficient market would not… could not reward something as simple as market beta.
My point is that it is conceivable that it would only be a matter of time before the size anomaly would be arbitraged to nothing.
Now the market is ruled by risk agnostic machines. Where does that leave us?
I was comparing the 300 stock model to the IWC ETF (Russell Microcaps). The sim assumes 0.35% slippage with $100K min turnover per stock and $1 per share. Nothing fancy in the trading rules other than a focus on stocks under $1B marketcap. Straightforward ranking system with rank>85 as a buy and rank<85 as a sell. It retains alpha if you increase that but turnover also increases. I wanted to lower turnover of portfolio somewhat. This truly is a simple ranking system built almost exclusively on 5 factors. I included 20% weighting towards an older Microcap system designed by Oliver Keating that I think most of us have a version of.
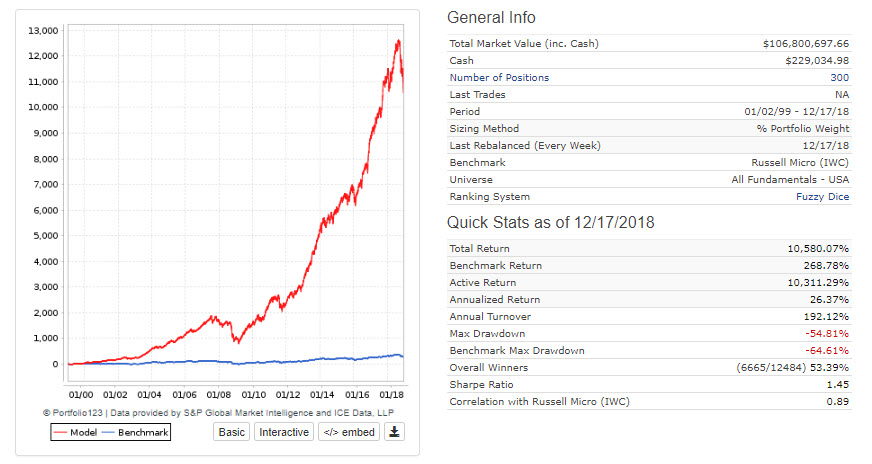
Here is the rolling 1 year period chart with 1 week offsets versus IWC.
edit: whoops - I wanted to replace small chart with big chart but now have 2. Not sure how to take old one down. Rolling chart includes 0.35% slippage on transactions.
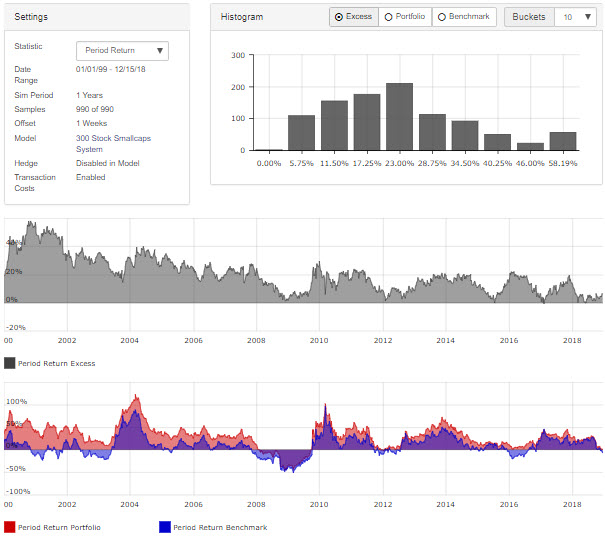
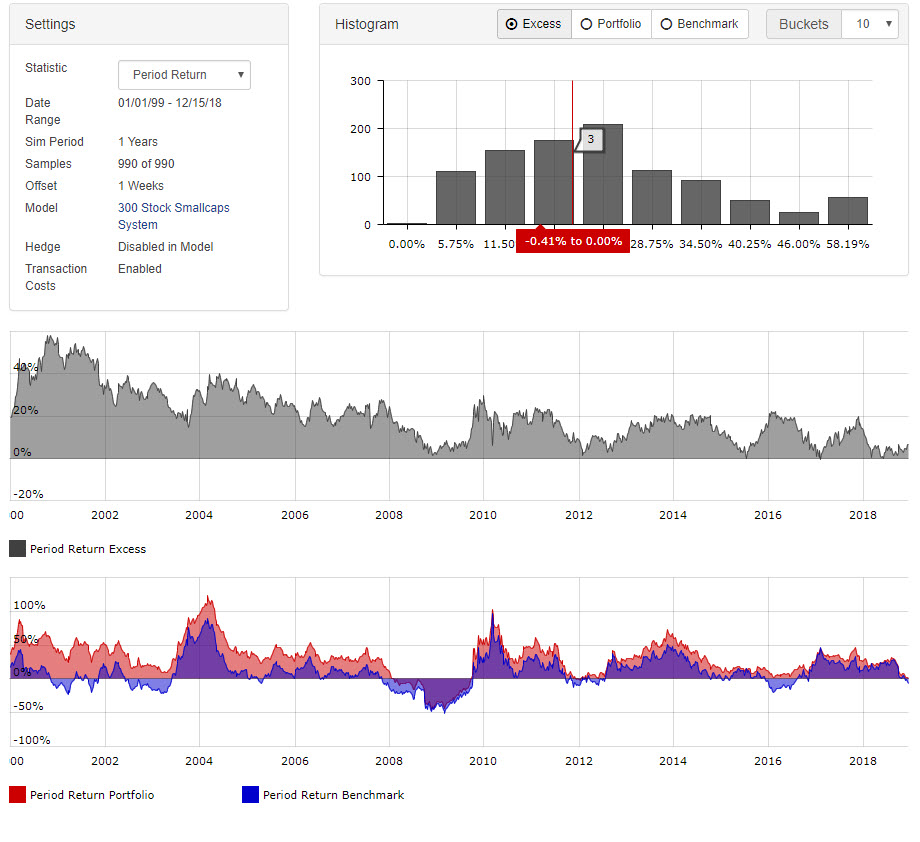
Great! Thank you for posting the data. Now, I’m inspired to go back and rework some of my micro-cap models.
Walter
My only advice is that less is usually more. If I have a system that only works on the top 15 - 25 stocks, I don’t trust it like something that works on 100+ stocks. And fewer rules are better. Can I add a bunch of stuff that lowers turnover and increases backtest return? Sure. Has it worked out the past 5 years? Nope. The simple returns of the top 100 stocks in each ranking system have typically outperformed any kind of curve-fitting fancy footwork I added later. Lots of focused 10 and 20 stocks systems failing but broader systems remaining robust.
The bigger issue is trying to find someone who wants to run this. I have tried over the past year to use it as my ‘payment’ into a working relationship where I design models part-time for a couple thousand bucks a month. So far all I get is disbelief. Just like another long/short system I developed that nobody wanted to run and said it was too good to be true. So I let Marc Chaikin run it at no cost. Hopefully it works for him and I get a recommendation in a couple year’s time. Having that on my LinkedIn account would be worth far more than selling the model for $10 or $15k.
First, I am already convinced and nothing more would be needed to convince me.
So, three things that could possibly help (two just questions).
1) Some of the people you want to convince are quants or quant-like, yes?
-
If you are a professional and paying CapitalIQ or S&P500 for data (or somewhat of an insider with P123 and can run it “internally”) can you download more data than some can at P123?
-
At a minimum (it is free to ask), ask Chaikin what it would take to convince him. And more specifically: “If I bagged this and used the out-of-bag data as cross-validation, then would you be convinced if the results are positive?” I bet you would stop him in his tracks and that he would say “yes” (after thinking about it).
Maybe not him but you could find some people that it would convince. And not as hard as you think: even if you had to find a Ph.D.student at a local university to help you with the script in R the first time—you could just run the script afterward. MathLab costs but it might be nearly pre-packaged and you could probably get support (or a statical consultant) to put on the final touches. Or just ask Cyberjo (was with P123) to take a couple hours on a Sunday. Get an iMac Pro with maximum RAM or borrow a couple of cycles on a parallel processor during off hours at P123.
If you just need to find one person to convince and you pitch it to enough people, I think this will be the final touch that will get your foot in the door.
BTW, I am not exactly sure that this (alone) would convince me because you have already optimized on the entire data-set but you should still see what Chaikin says. Remember, I am already convinced and you are not trying to convince me. You are trying to convince some random quant with a bit of jargon: and only because he controls some money.
Denny Halwes has some of the best recommendations about this: with his even an odd universe recommendations. I assume he got this from his engineering experience. But wherever he got this, no one would argue with what he says regarding validation and I cannot add to it. And Denny has adapted what he does to P123 with no special software, data downloads or computers required!!! But you have already mixed the universes for this system.
Denny’s methods are preferable in a number of ways and his methods are straightforward. But he may not include enough jargon to convince a random quant;-) However, using the technical term for what Denny recommends, Criss-Cross Validation, might be a start. And you could probably add this jargon for any new system—never mind if it looked a lot like the system you are highlighting. You would be forgiven for this: All of us (including Marc) are data snoopers after all.
Final note: bagging is a type of Ensemble and there are a whole bunch of people over a Quantopian who think it is cool or would think it is cool once the meme got around.
FWIW.
-Jim
Thank you for the good ideas. I have tried various approaches for years and am not complaining about the great people I have already worked for. It would just be nice to have a steady gig that pays even half as much as when I ran my janitorial business part-time. I can show firms years of out-of-sample returns on my ranking systems that I developed in 2012 and 2013 - but it still rarely works into anything.
On another vein, I coded in the WorldQuant challenge this year and did very well out of sample. Got a phone call asking me to on-board but 5 months into the background check (and still waiting) they have reservations due to my consulting work using P123. Hopefully I will get the verdict before another 5 months pass. I also just found out that the average quant (part-time research consultant) makes about $25 a day there. No lie. I asked other consultants about the likelihood of wages plus bonuses equaling $30K in the first year and was laughed at. Maybe in 3 to 5 years with a lot of hard work I was told. There is a reason why they ‘offer this unique opportunity’ to bright minds in developing nations.
The hedge fund Noviscient was willing to forward test and then run my long/short strategy but I had to send them each trade by hand. Running market neutral in P123 doesn’t work very well in Live Ports. You need a long book and a short book and then constantly adjust the amount of cash in each portfolio by hand. A lot of manual adjustments so in the end I told them no. But if ever P123 improves the interface for market neutral and allows exporting APIs - that’s the first place I’d go. You get 20% of the gross returns but they keep 10% of that back as a buffer against drawdowns. When you close out your strategy you get whatever is left of that other 10%.
You’d think there’d be a fund or a small firm where you can hand them like 5 decent strategies and they are willing to take a punt with you for like $2,000 - $3,000 per month designing more strategies for them. This doesn’t seem like too much money when I look at what they already pay out and how poorly designed some of the strategies are. And if it doesn’t work out in 6 months - they can end the relationship and keep the models.
Marc Chaikin has an account at P123 and reads the message boards. I don’t know him other than a brief email exchange but he seems like a stand-up guy. I would encourage him to comment on the post if he is reading. What does it take to be taken seriously? I think submitting a script to Hollywood is easier IMO. I really need to buckle down and learn Python.
Will keep plugging away, that much is for sure. Thank you for your good ideas.
Believe me, I get wanting to do what you love all day long.
But there is real money in the janitorial business. Money that could be invested in that port/SEP-IRA……Well, until you did not need the janitorial service.
But I reeeally get it.
Best,
-Jim
Kurtis,
I have sold to Renaissance Technologies before.
The biggest issues for the funds were liquidity, capacity, alpha-decay, and out-of-sample performance.
For the first two points, big annual returns on $100,000 aren’t going to move the needle nearly as much as above average returns on $100,000,000. This is not saying that small cap strategies are not valuable, but rather that they do not align to asset managers’ incentive structures. Moreover, the will discount them for liquidity risk and market impact.
The next two points are also related. Anyone these days can produce good backtests and boast of robust out of sample performance. But statistical cross-validation is not what they mean by OOS. They will need to look at real account performance in order to foremost assess the rate of alpha (information) decay using real dollar terms. Moreover, real money results will helps them with the first two points as well.
Personally, I think it would be helpful for your pitch if you could give some additional color around these points. Fund managers may not ask these questions up front, but they will be thinking about them regardless. If you don’t give them that information, they use what they already believe as a placeholder.
David,
I actually agree with this (assuming you have cross-validated the backtest). But it is also a NoBrainer that one would bag what works on the backtest or boost a decision tree.
Not to mention a rational stack here or there. Just a guess but I bet they knew what it meant to “bootstrap” long before I had ever heard of it.
James Simons is a mathematician that…… Well maybe he just looked at the equity curves of out-of-sample stuff that anyone else could see.
Small point. One that I will amend YESTERDAY when someone shares with me what it is—exactly—that those Physics Ph.D.s at Renaissance Technologies are actually getting paid for.
Hmmm. Do you have any insight into this?
Thank you in advance for sharing. But for now I will assume that they do not always wait 10 years for their out-of-sample ideas to show significance (probably).
And I was that first to say that much of this is “jargon.” Jargon that can be heard in the cafeteria of many of the quant funds, I bet. But no reason to think that one would have to talk their language while eating there. Not that I will ever have to worry about how to dress, talk or more to the point: get a job there;-)
-Jim
We sold them a series of signals that were based on having a private wire. I cannot really comment any further on this.
But I can speculate on what else goes on inside the institution: statistics - How did James Simons clinch that security prices didn't look random? - Quantitative Finance Stack Exchange
So cool and thank you!!!
You cannot go further but probably explains your interest in Kelly Betting.
BTW, I always figured Simons was secretly using classic finance and discounted cash flows. As soon as I understand this link I will be able to prove it;-)
Anyway much appreciated. And I do not know why I like this stuff so much (and defend to excess). Maybe same reason Kurtis and David do what they do so well (and enjoy it).
My apologies.
-Jim
hemmerling, what happens if you change the universe to Russell 2000? Similar outperformance?
Beating IWC consistently using small caps is a heck of a lot easier than beating SPY consistently using small caps. And beating IWC says nothing about whether there’s a small-cap premium or not . . .
I sort of agree with this but really it is hard to say. Some microcaps have spreads of 1-2% which is what? Half of your annual alpha? Plus factor in liquidity risk, wider spreads , greater volatility.
I think companies in the 500M - 5B range are more in the sweet spot.