I keep reading the random forests and extra trees regressors are forgiving of noise variables.
I note: Those articles are usually about i.i.d. data. Often manufacture data. But not stock data usually (stock data is not i.i.d.).
So how forgiving is the Extra Trees Regressor model with stock data? I started doing this with a ranking system that has feature I know and love. Frankly: pretty good but I want better. Maybe I am too selective in my features and if so maybe I just need to throw in the kitchen sink and the a higher intelligence (P123's AI) can sort it out.
An obvious step might be recursive feature elimination starting with the kitchen sink thrown in.
I was hopeful that P123's mutual_information_regression would be helpful here or [SelectKBest](SelectKBest — scikit-learn 1.5.0 documentation using the mutual_information_regression metric but I think NAs are making this method not too useful . But that just means RFE needs to be done with a different metric. Just good to know.
Or more simply: more features are not always better all of the time. With Extra Trees Regressors anyway.
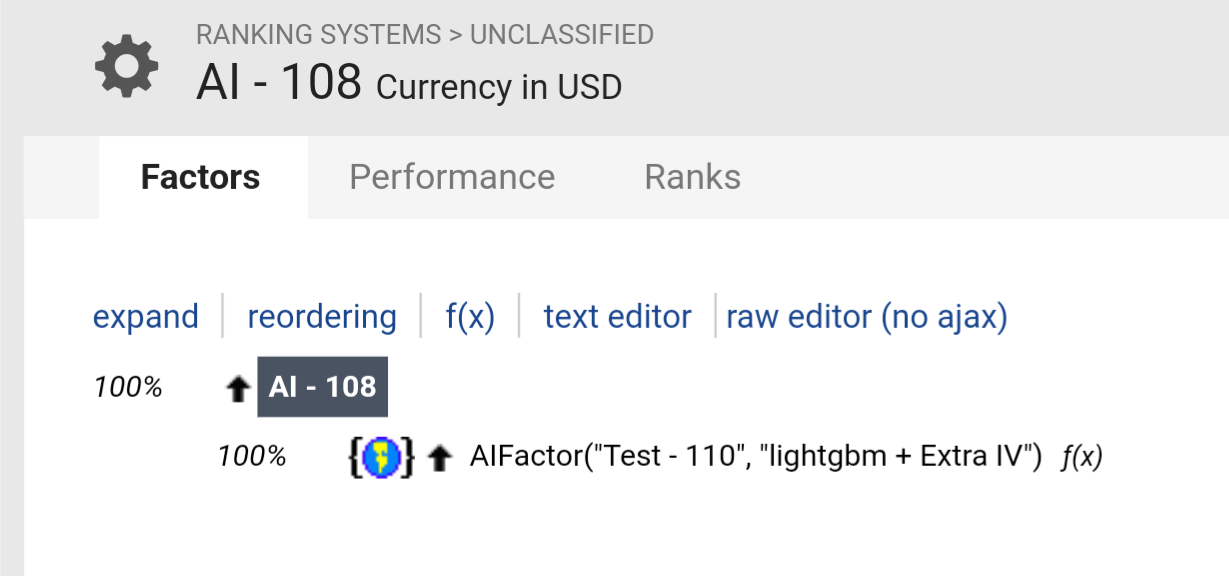
Hi @Jrinne! Could you please share the comparable simulation that matches these AI Factor results? I’m trying to reconcile these results with the other elements of the site, so it would be really helpful if you could include the details for both the AI Factor settings and the simulation settings. Thanks a lot!
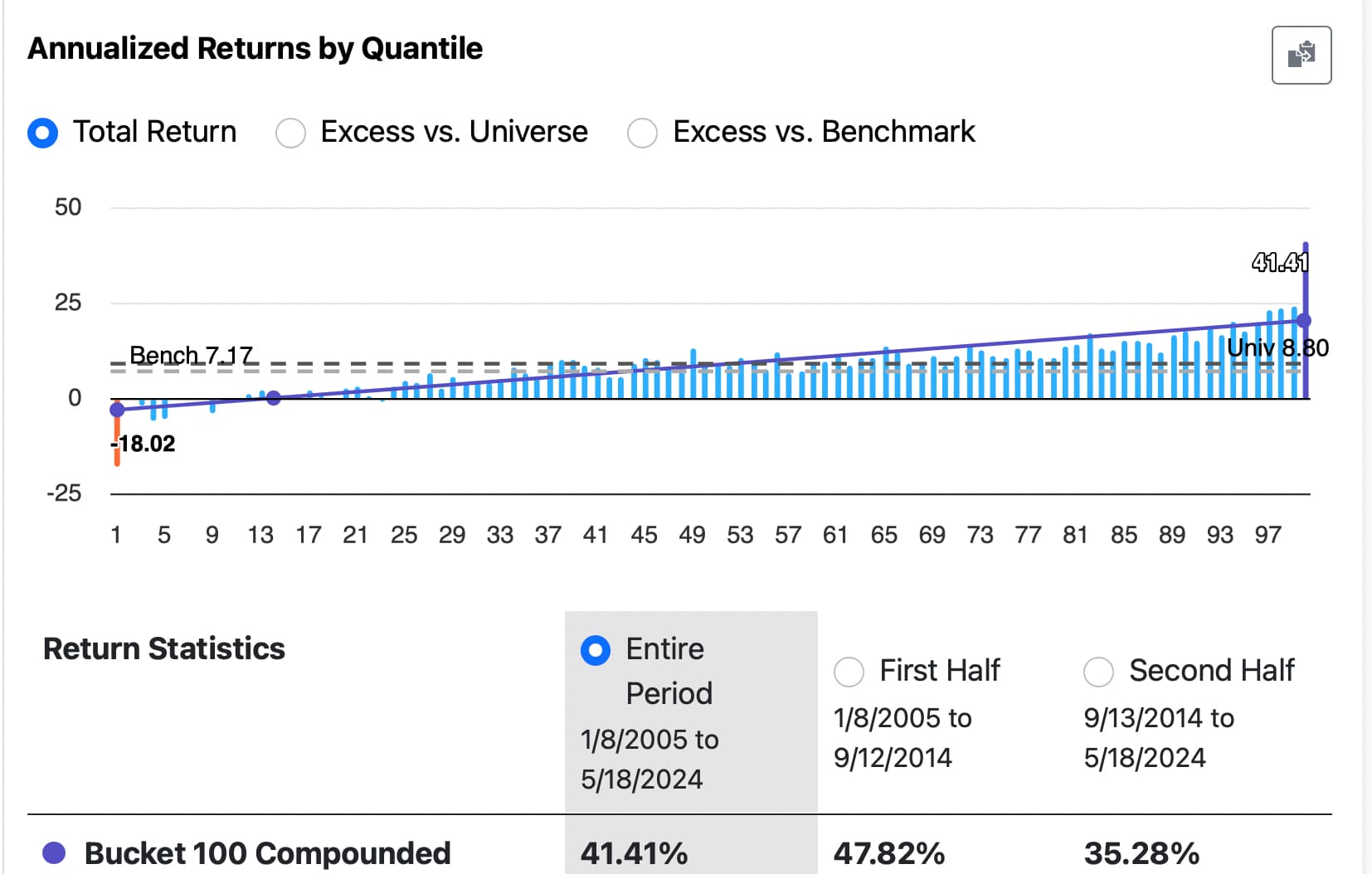
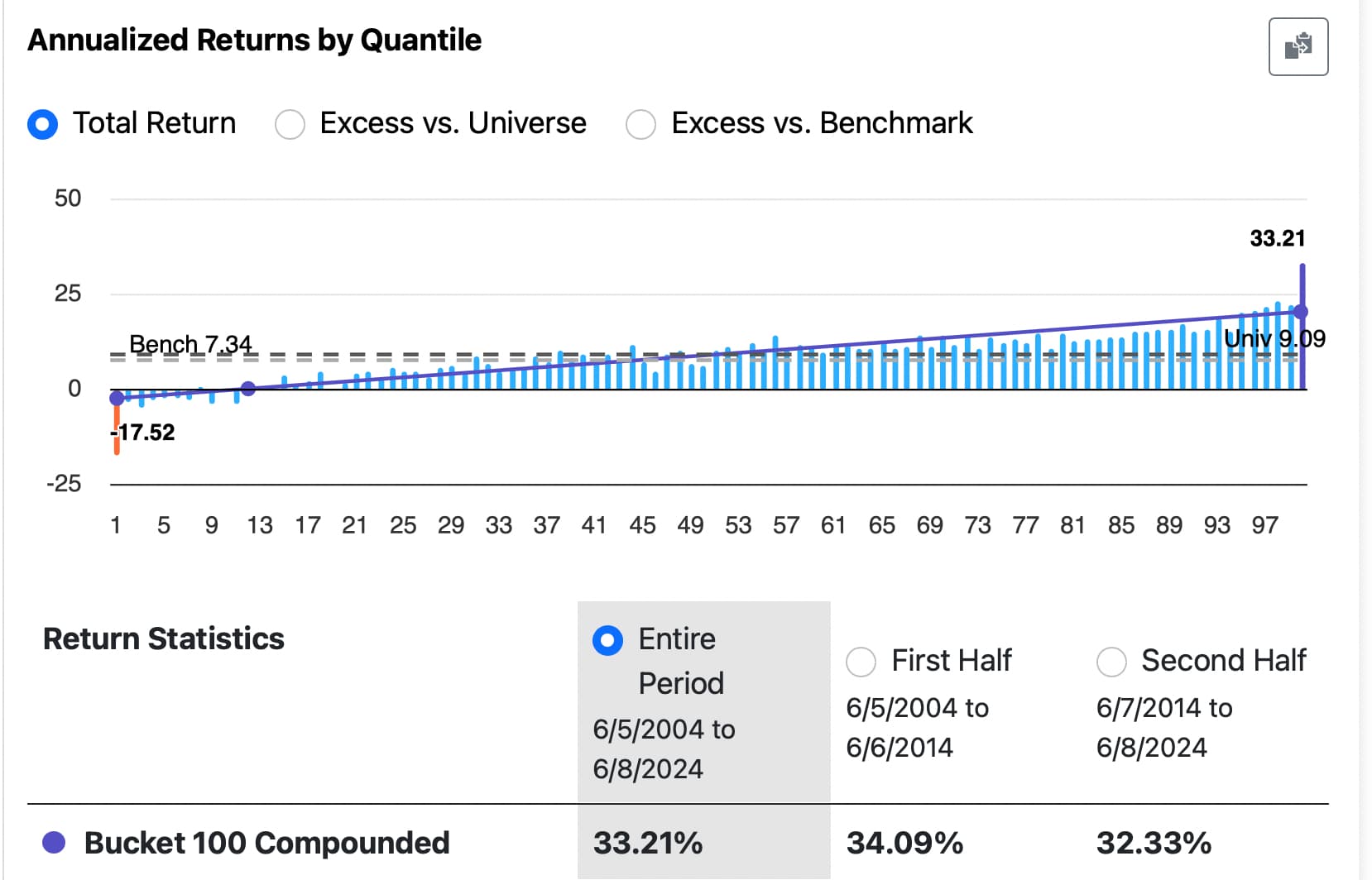
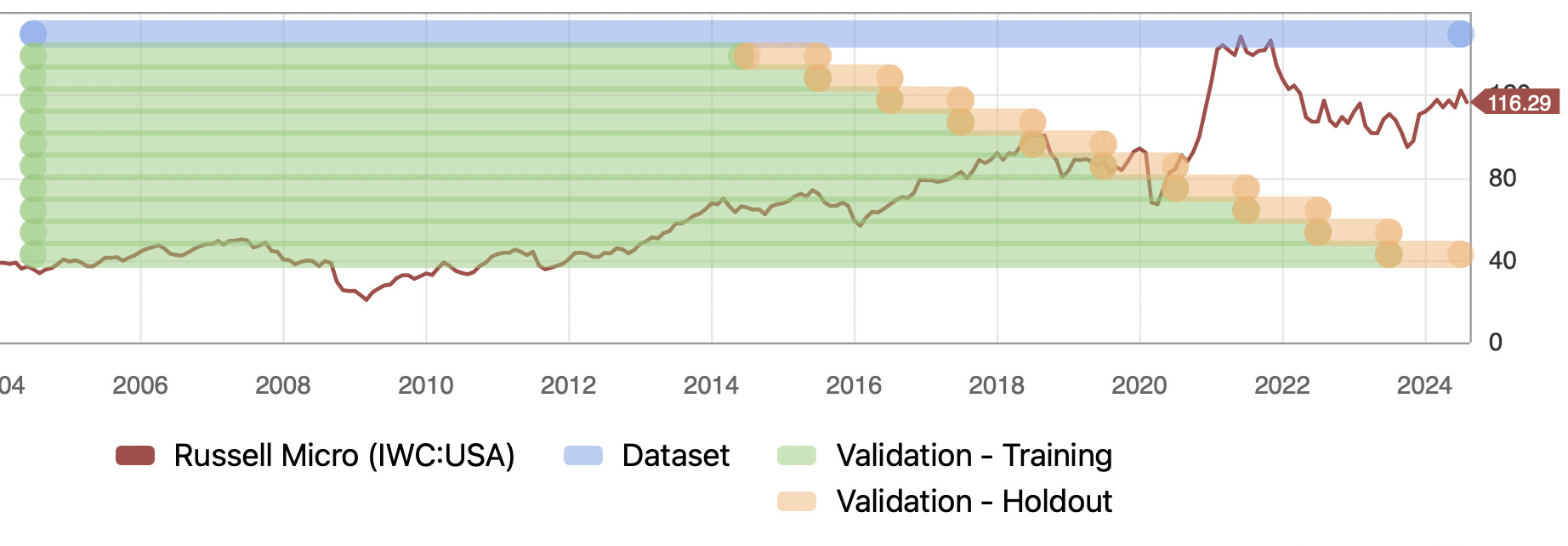
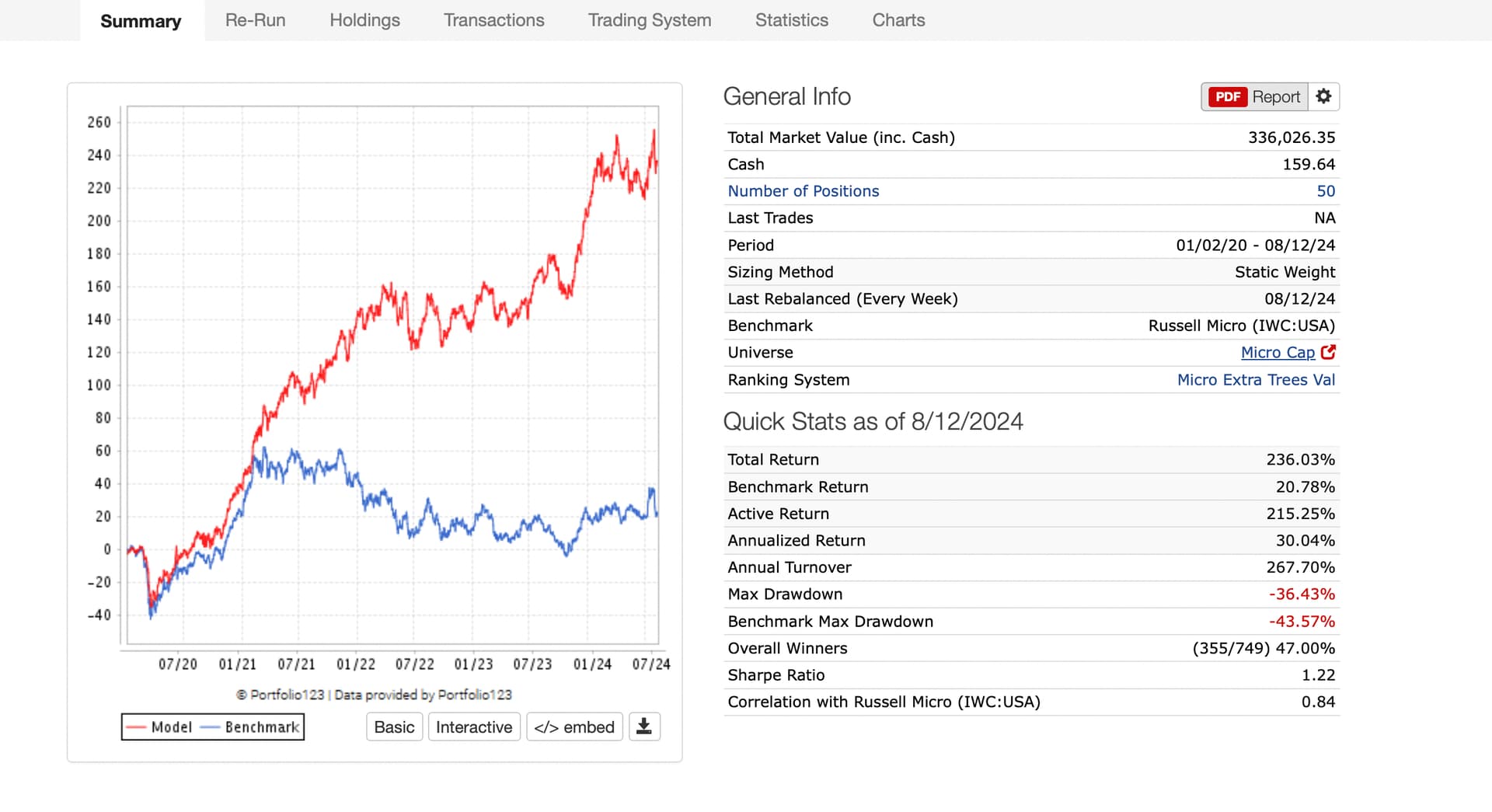
Hi Korr, Here it is. This ranking system was not trained with any data (including target data) in the sim period. But as you can see above, I have run previous validations over this period and this is not a holdout test set. Therefore, it is an open question as to how much these results would regress toward the mean out-of-sample. It would probably be a function of how many validations I have done with this method and features (as well as how correlated each trial was to previous trials). I am not funding this and I am aware of the limitations of this study meant to understand how good Extra Trees Regressors are at selecting which features to use (done at each split) using a larger basket of features. Additionally, there is look-ahead bias in the original features selected for this study:
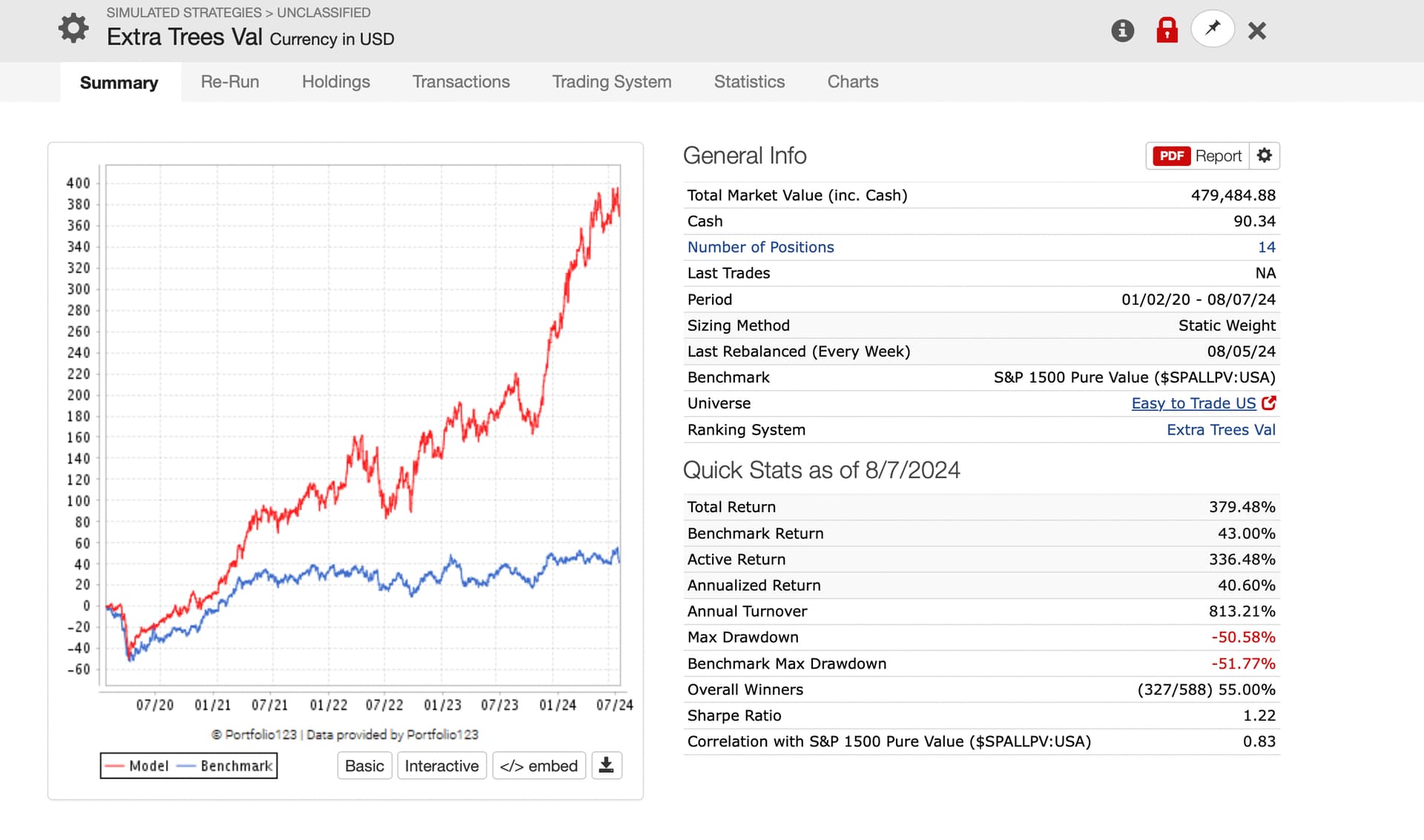
Optimizes to a relatively low turnover (Trading System screenshot for sell rule). Because of slippage I assume. Decline from performance results of the AI model with no slippage would also suggest slippage is important, I think:
Thank you ZGWZ for getting me to look at this. And for you impressions as well.
Another way to mitigate the problems of trading costs would be to go with 50 stocks (less money is required for each individual stock with less trading for each ticker when using multiple limit orders say).
I would have thought because of transaction costs my model wouldn't work at all in such a universe in which more than half of stocks have a variable transaction cost of 5%, but it looks like it will. It is so amazing.
It reminds me of the breakthroughs in the history of science that have come about because of mistakes. I can't even believe the results. Maybe those stocks are not untradable as I thought before.
Did you add in a lot of features to get positive returns over benchmark? I tried with even just some existing ranking systems like Core Combination and Small Cap Focus, they did OK but not over benchmark. These have about 60-100 features. I have some other custom rankings that may do better.
UPDATE: My question is does it make sense to use a smaller number of features that are generally targeted? I didn't get good results with Kitchen Sink either.