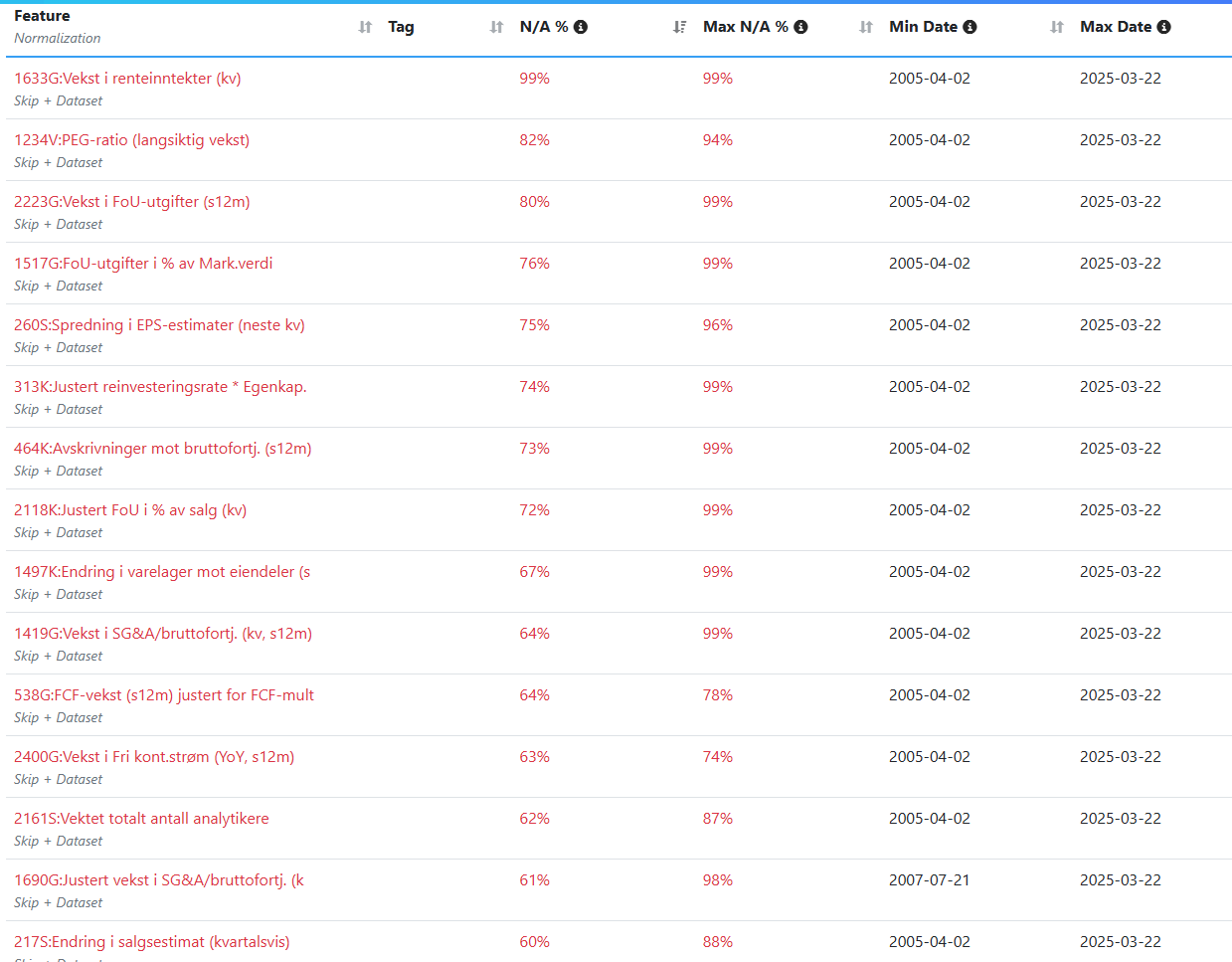
I am currently cleaning N\A entries from the feature factor list in AI-factor. Does anyone have input on where you set the threshold for how much data can be missing to still keep the feature? Below 50% total N\A?
I see that there is a significant amount of N\A in European data, particularly at the beginning of the period, as I expected, and this is somewhat better in the USA.
I have been trying to only train using near zero max NA so my first AI factor will be a technical one with low/no NA. So far the validation looks great, but just looking to learn. It will also be the first technical system I build.
For my main/fundamental-only model I have been rewriting everything to try to get to very low near zero max NA as well which will require separating universes such as analyst vs no analyst coverage (or a number of yes/no booleans in training). Curious to hear what percentages people have been ok with but I think maybe I would want the max to be less than the trim% if I cant manage zero N/As like my first one. (I dont think I would remove a feature though since I put it in to select stocks based on it so I would modify it or use a different universe or a boolean)
Do NAs affect tree models? With a few caveats I think they cause no harm whatsoever!
For example, if a feature has all missing values, the model simply ignores it during training — it won’t be chosen for any splits and will have no impact on predictions. This typically results in zero feature importance, and the model’s behavior will be unchanged if the feature is removed entirely.
If a feature has some missing values, tree-based models can still split around the NAs if doing so improves predictive performance — specifically by reducing mean squared error (MSE) or an other metric you chose.So, the presence or absence of data itself can become part of the decision logic.
I think there would be a problem only if the number of NAs is different over different periods or the rules for being an NA change over different periods. Other wise they cause no problem.
The only other caveat is that the presence of NAs doesn’t automatically make a feature valuable — in fact, missing values reduce the effective sample size, which can increase noise and dilute signal. So while NAs themselves may not harm the model directly, a feature with a large number of them can still behave like a noise variable simply because there’s too little consistent data for the model to learn from. That said, I wouldn’t rely on a fixed threshold for the number of NAs to make that determination — the real test is whether the feature contributes meaningful signal despite the missingness.
P123’s AI/ML removes some features I would like to keep because of NAs and that is one reason I am using downloads for now.
Keep in mind the NA are zeroed out. They dont show as missing. So a missing estimate is an estimate of 0 so it should be bad for training. A lot of zeros also affect the mean. My plan is to have a boolean feature for yes/no coverage to get around some NAs like this and trim could help with the mean..
TL;DR: You’re making a great case for native handling of NAs — which is fully supported by tree-based models like XGBoost and LightGBM. Thanks for raising this!
Still, I think for a tree model, it can just split all the zeroes off to the left (or right) — or not — depending on whether that improves predictive performance. If it doesn’t help, it won’t split there. I get that for a single stock, a zero might represent a true value (e.g., an actual estimate of 0), but that’s usually just one or a few out of 4,000 stocks (depending on your normalization). It’s an outlier in many cases — especially with rank normalization. For the rest, those zeroes are effectively just stand-ins for missing values.
If there’s information in the missingness itself, a tree model can actually learn that. It can treat the “missing = zero” pattern as a signal — if it helps predictions — which is one reason tree models tend to be so robust in these situations.
In fact, many modern tree-based algorithms now include native support for missing values, specifically to preserve that signal. But even when native NA handling isn’t available, the pattern of zeroes (as NA proxies) can still carry meaningful information — and the model can still split on it.
Some advanced members — seeing the potential advantages of preserving NAs for certain features — have requested that P123 allow native NA handling. Marco mentioned at the time that he would look into it.
In the absence of NA handling for now I would say it makes sense to introduce a boolean to help the model know which zeros are real and which are missing data. What do you think of this approach? I still think a sales estimate of zero and a missing estimate are two very different things I would not want the model to confound
Great idea!. For ranks I have proposed making NA values -1.Which is a separate value from any stock this is not NA, of course. They would always be split to the left but would be a value only for NAs. I think Pitmaster liked that post.
But with XGBoost it will decided whether to put NAs to the left or the right of the split depending on which method improves the metric (usually MSE). This is a MUCH better..
For now, I am for any workaround including your idea.
Do I understand correctly that you do not allow any N/A () values for the data in your features?
I see that only the feature with N/A values exceeding 35% is marked in red. What is the reason for this? Is there any academic assessment behind it?
What is the easiest way to remove the features with high N/A values? Do I need to create a new factor list and remove them one by one? And if so, do I need to run a completely new round of the AI factor test, or can I remove the features with high N/A values directly in the AI test and run it again?
So for the first system I am making I am not allowing almost any NAs which was easier because it is based on price and volume data.
For my upcoming fundamental system I am being very careful with NAs as they get turned to zero and can change both the mean when z-scoring and the behavior of the model when splitting, binning or predicting. All my factors are custom formulas. I went through my entire 250 ish custom formulas (and my universe to some extent) and tried to do things like fallbacks and substitutions or set to zero within a much larger formula to reduce or eliminate NAs using the formulas themselves.
For example if float is missing use market cap. If quarter is missing fall back. I don’t think I will be able to get it to zero but it is drastically lower than when I first loaded the features.
For those where no real substitute exists such as estimates I might separate stocks with no coverage into a separate model but I am still thinking through all ideas..
Just to clarify, NAs are filled after normalization. So 0 carries the same meaning across all normalization methods, namely the middle of the distribution. While this may still have an undesired impact on features and predictions, NAs are at the very least consistently treated as neutral.
(Rank normalization was changed in December to make it range from -1 to 1 so 0 would be neutral.)
Quick Trick: Restore NAs After P123 Rank Downloads for Native Handling in XGBoost and LightGBM (at home with downloads).
When P123 exports ranked factors (in the [-1, 1] scale), all NAs are replaced with 0. Here’s a fast workaround:
df_rank[df_rank == 0] = np.nan
Why it works:
Only one non-NA stock can have a true rank of exactly 0. If you have many NAs, this single misclassified stock won’t matter — and your model (like XGBoost or LightGBM) can now use native NA handling (at home with the downloads).
Result:
One valid stock will be incorrectly marked as np.nan, but all true NAs will be correctly restored. A very small error — and a practical tradeoff if you want models to learn from missingness.
Why Native NA Handling in LightGBM (and XGBoost) Matters
LightGBM doesn’t just ignore NAs — it handles them natively and intelligently:
First, it finds the best split without the NAs.
Then, for each split, it tests whether placing the NAs on the left or right of the split improves the loss (e.g., MSE).
The direction that gives the best split (lowest MSE) is used.
This allows LightGBM to treat missingness as a potential signal. For example:
A stock missing an earnings report might indicate trouble — that absence itself could be informative.
And because the algorithm evaluates NA placement at every split, it can capture nuanced patterns in how missing values relate to the target.
Mathematically, this always improves (or at least maintains) the loss — so native NA handling is often far better than imputation or discarding missing data.
There may be concerns about features with NAs in P123, but when using XGBoost or LightGBM at home, NAs are not a problem — in fact, they may even be an asset.
I would be interested in discarding the NA myself unless I knew the reason it was missing was somewhat consistent across time and into the future. The idea of letting us discard them for splitting seems appealing. I can see the appeal of letting them in though.
Full agree, it needs to be consistent. I said that above too. I agree 100%
One subtle point within P123: ,NAs are always given a fixed value (0) — and when using that data in the models, the NAs will always be split left or right arbitrarily, without the algorithm re-optimizing split direction like LightGBM does. So not ideal. But if the NA pattern is consistent, that may not be harmful in practice.
This is particularly important for tree models, because they can keep splitting until the NAs are effectively isolated.
If the NAs introduce non-linearity or break monotonic relationships, trees are uniquely equipped to handle that — they don’t require linearity or monotonicity the way linear models do.
In other words, you can probably recover some of the information from missingness within P123 still — despite its less-than-optimal handling of NAs for models like LightGBM and XGBoost.
If and only if, as you say, the NAs are consistently handled and appear in similar numbers across the training period.
TL;DR: Sometimes P123 plays close attention to important statistical and machine learning concepts so we don’t have to.
That change has an elegant implication—it places the y-intercept at zero for every factor, which means we can evaluate slope without needing to account for the intercept or consider whether to force it to zero.
And because NAs are filled with 0 after this normalization, they now have exactly zero leverage in any slope-based model or rank-vs-return regression. That eliminates the concern that missing values might distort the regression line.
For factor downloads that are separate from the AI module, note that as of my last test in August, the ranks were not zero-centered.
That may not matter for tree-based models, but it can introduce bias in linear models.
If you’re using Python, consider applying StandardScaler() (or another method) to zero-center and scale features before optimization — especially if you’re not using the AI pipeline, which handles this internally.