All,
I fear that I am about to ask a question that is so simple, so fundamental, one whose answer is so obvious that it will be kin to asking “What day of the month is the 4th of July on?” Well, I am going to ask it anyway.
When each of you is developing a ranking system and considering adding a new factor, (1) how do you decide what weight to give that factor, and (2) how do you determine if adding the factor at all means the ranking system is better or worse?
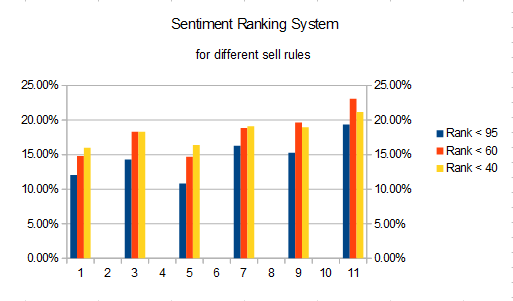
I ask this because I recently decided to find out why the momentum ranking system performed so poorly in my tests (see a newbie's exploration of the core combination ranking system - part 2 discussion topic Momentum). I learned that partial causes of the poor results were my simulation conditions of (1) only 5 stocks, (2) sell rule of “Rank < 95”, and (3) stock universe of S&P 1500. Once I changed the portfolio size to 50 stocks and the sell rule to “Rank < 60”, then I got a much more respectable CAGR of 9.96% for the S&P 1500.
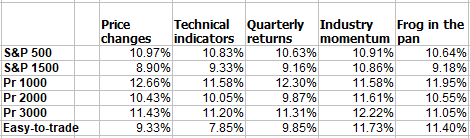
To determine what contribution each of the original 4 factors of momentum (price changes, technical indicators, quarterly returns, and industry momentum) along with my implementation of “frog-in-the-pan”, I decided to run 31 different trials across 6 different stock universes, namely S&P 500, S&P 1500, Pr 1000, Pr 2000, Pr 3000, and Easy-to-trade. The 31 different combinations derived from deciding to give equal weights to the 31 combinations of factors, taken 1 at a time, 2 at a time, 3 at a time, etc., with each factor selected being equal weight to the others. So now I have all of this data, but I am not sure what I am seeing. The data gives credence to the idea that industry momentum is the best factor. My “frog in the pan” component seemed to be 2nd best, and the other 3 factors other weights. But this is not always the case. While I have a notion on how to determine the weights for each of the factors, I hope I can get you folks’ inputs on how each of you does it.
Thank you.
Cary