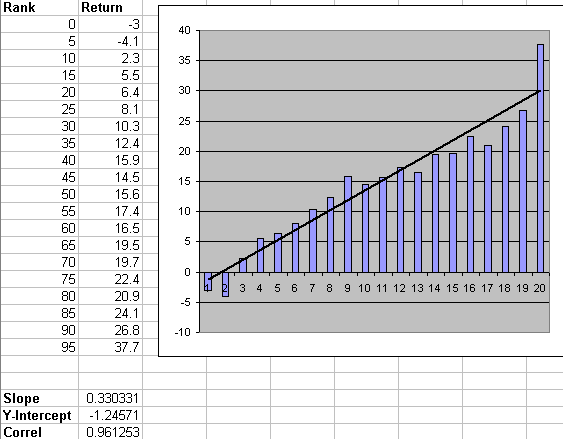
Marco is on the right track with his metrics:
slope
correlation
delta
It does not make much sense to me to only focus on the last bucket (however, there are exceptions, as discussed below; therefore the user ought to have flexibility in their evaluation of the Rank System). I agree that if you find a last couple of buckets that have high annual return in your backtesting, this will lead to some nice returns in your simulations. However, the key word is ‘simulations’. Unless all of the research in statistics for the past 300+ years is incorrect, there is such a concept as statistical significance: in this case it means one would want to see upward sloping, smoothly increasing buckets from left to right, with each bucket higher than the last and ideally the last bucket being really high so that the simulation looks great. Marco has proposed a mechanical evaluation of that desired scenario.
A close approximation to statistical signficance would be to look for:
increasing buckets from left to right
smoothly increasing returns from left to right
each bucket is higher than the next
Basically, Marco’s suggestion of slope, correlation and delta, together are a good approximation of statistical significance for the ranking system.
How about a happy compromise for those who only want to focus on the last bucket (i.e., the last delta; or, only the furthest right bucket vs. the bucket to its left; and therefore the ranking system has zero statistical significance and probably zero predictive ability) and those who would like to survey all of the buckets (i.e., all of the deltas; starting on the left, compare each bucket with the one previous to it; and therefore a simple, layman’s, but likely effective, approximation of statistical signifcance and more probably future preditive ability of the Ranking System)? More on this below…
Marco, et al.,
What about another delta calculation that is the sum of the deltas between each consecutive bucket? That is; instead of the delta of only the highest and the lowest bucket or the highest and the second highest bucket (some people seem to be focused only on the top bucket), why not calculate the delta between all of the consecutive buckets and take their sum or other statistical formulas? I guess this is similar to a combination of correlation and slope. If you think about it, this is basically what we do when we visually (qualitatively) look at a ranking system’s performance as displayed in the form of annual return buckets and it is statistically (quantitatively) what we do when we use various statistical metrics. Essentially, ask the question: is the last bucket high because it is a fluke that is non-repeatable, or are all of the buckets lined up one consecutively higher than the next, which would tend to indicate that the high last bucket is not a fluke (I concede there are exceptions, but these exceptions usually have a fundamental market force that makes it persistent, therefore the lone high bucket that is persistent and profitable on a forward-test basis should be the exception of a ‘Good’ Ranking System, not the rule).
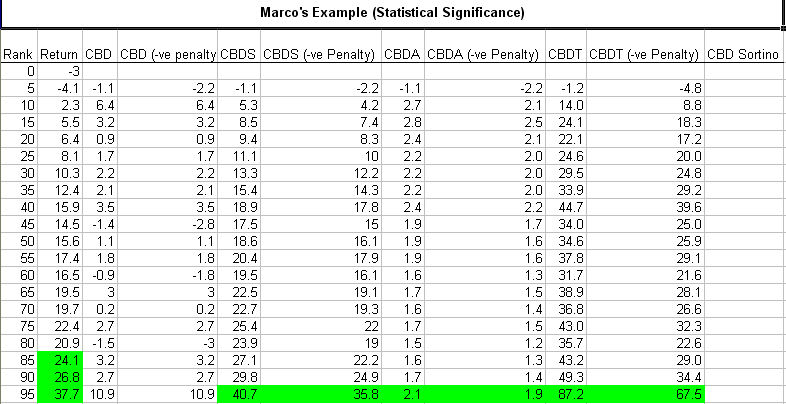
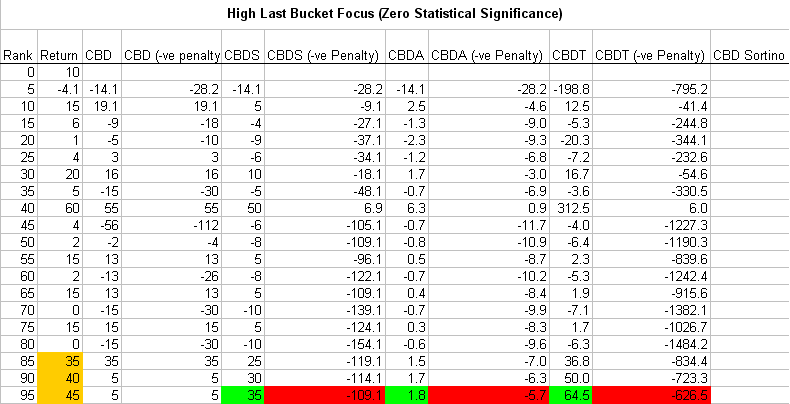
The difference between two consecutive buckets could be known as the Consecutive Bucket Delta (“CBD”). The sum of all of the CBDs could have another TLA (three letter acronym) or even a FLA (four letter acronym) ;). The ‘Consecutive Bucket Delta Sum’ (“CBDS”; or “CBD” or “CUBIDS”, not be confused with “CUBITS”). The higher the CUBIDS the better the ranking system (and the bigger is Noah’s boat). The CUBID would be calculated as follows using Marco’s example at the beginning of this topic (I have attached some PNGs and the work sheet). The calculations include a “(-ve Penalty)” for buckets that drop in value. Why? Because otherwise the buckets could go up then down up then down, etc, and then a few buckets at the end or even just two consecutively higher buckets by a large amount would skew all of the calculations. So, the (-ve Penalty) puts the Rank System in the penalty box for 2 minutes; i.e., the (-ve Penalty) multiplies the negative CBDs by 2 and is similar in flavour to the concept behind the Sortino: penalize the downside deviation not the upside deviation. (Quite frankly, the Sharpe ratio is useless IMO, not only for that reason, though; the highest Sharpe ratios are found often with systems with ridulously high turnover, and which have not properly accounted for transaction costs; and the Sharpe is dependent on the period used for calculation, etc.). The worksheet is self-explanatory if you look at the formulas. If someone has an Excel Sortino formula, maybe they could add that in. Hopefully, it does not contain errors, feel free to correct, add, etc.
Here are the acronymns (don’t shoot the messenger for trying a crude first approximation at a ranking system metric; and excuse the silly acronyms :). Instead of “(-ve Penalty)” it could just be CBD- for example.
CBD = Consecutive Bucket Delta (delta is simply the fancy math word for ‘change’)
CBD (-ve Penalty) = If the delta is negative then multiply that -ve value by 2 (Marco, this value of 2 c(sh)ould be an option for the user: for instance if you really do not care about an upward sloping bucket ranking system and are OK with a purely random, non-significant ranking system with which to trade your money, then set this value at ‘NA’ (or, ‘1’); or if you really like punishment set it to -2)
CBDS = Consecutive Bucket Delta Sum (Sum all of the CBDs moving left to right)
CBDS (-ve Penalty) = Same as the CBDS, but sum the CBD (-ve Penalty)
CBDA = CBD Average
CBDA (-ve Penalty) = Same as CBDA, but average the CBD (-ve Penalty)
CBDT = CBD Total (CBDS * CBDA); use multiplication to accentuate the quality (or lack thereof) of the Ranking System
CBDT (-ve Penalty) = Same as CBD Total, but with the (-ve Penalty): (CBDS (-ve Penalty)) * (CBDA (-ve Penalty))
The two screen shots show a ‘Good’ Ranking System and a ‘Bad’ Ranking System.
Green means good. Gold means really good; that is, at first glance the three consecutive high buckets in the ‘Bad’ Ranking System look very appealing: it’s gold!
Which is why the negative penalty is introduced: a random system that does not show any statistical significance (i.e., not having some or all of the qualitative factors we discussed already: upward sloping consecutive buckets, etc.; or the quantitative factors: slope, correlation, the delta, and the CBD family of statistics) should be eliminated (at the user’s discretion, of course, based on their prior settings for how they wish their Ranking Systems to be evaluated).
To reiterate, it is best that the user retains flexibility: they must have the option of choosing/customising how they want their Rank systems evaluated. Therefore, the user could rank by ‘High Last Two Buckets’ or something like the CBD concept: whatever floats your boat. I do concede that sometimes there are buckets at the extremes that probably do have statistical signifcance, but usually one would want a Ranking System that has a high CBDT (-ve Penalty).
As with all good products and services, especially software, the ability for the user to customise their ‘experience’ is paramount. We could debate what makes a good Ranking System for eternity, but a few tools like slope, correlation, delta, CBD Family, and high last few buckets, would give ample flexibility for every user.
Lastly, I left the CBD Sortino blank for anyone who has an Excel Sortino formula.
P123 Ranking Metric.xls (27 KB)