Let’s say you have put in quite some time to construct factors that seem to make financal sense to you. You also went on to test those factors individually by ranking them within an appropriate universe (as described here: NA negative vs neutral effect on buckets in Rank system - #6 by abwillingham) and you have done so untill now by eyeballing the buckets.
At a certain point you have collected a ‘large’ amount of factors that at least make some sense and seem to have a linear relationship with past returns. You now want to rank those ‘direct’ factors (so excluding marketcap and accrual type factors that have more of a augmenting nature) via the ranking system. Or in other words you want to rank your ranking systems of individual factors.
I’ve tried coming up with a ranking ‘score’ quite similar to the ones discussed here: How to mechanically assign a score to a ranking system. Using for example the slope, correlation and a function that counts the number of increases from one bucket to the next.
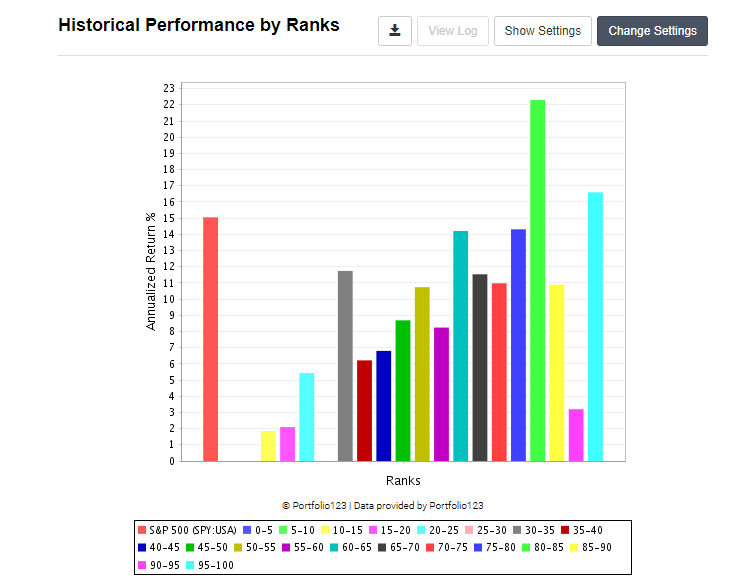
However, I found that sometimes factors in ranking systems have a high slope or correlation, even though I wouldn’t assign a high score to that factor by eyeballing it. See for example the image attached.
The slope that I get is around 0.75 and the correlation 0.73. However, the big drop in the last few buckets, as well as the number of empty buckets would be cause for concern for me.
How would you suggest I go about this? I’m very interested to hear how others have dealt with this issue.
Do you have a suggestion on how to program the weighted correlation or how to compute it in Excel otherwise?
Currently I’m using the sum of 4 metrics: slope, correlation, the ratio of upticks vs total buckets and a standardized version of maximum drawdown that I made up my own. That seems to work reasonably well as well.
But I’m definitely interested in your suggestion. Have you utilised it with success?
Not sure about how to rank or rate things as described, but first thing is I’d go back to the drawing board on that factor that falls apart above the 85th percentile and figure out why it’s behaving as it is and try to find a way to restate the ranking if possible. There may be a way to clean it up or not. Sometimes at extremes some non-representative or unexpected things can be happening in calcs.
Thank you for your post and the link to the older post. They got me thinking and trying a few things.
Thinking about your post I realized that because of the weight I put on a factor and the factor correlations most of my stocks will will be ranked very high (e.g., in the top one or 2 buckets of the rank performance test).
This might be best handled by comparing that bucket to a random selection of stocks from the universe or the bottom bucket. Maybe use a t-test.
The ranking system you show fails this test.
But sometimes an individual factor will have a wider range of ranks in my ranking system.
For the latter type of factor I would like to know that generally a stock with a rank of 67 will perform better than one with a rank of 41. For this you want to know what’s happening with the whole ranking system.
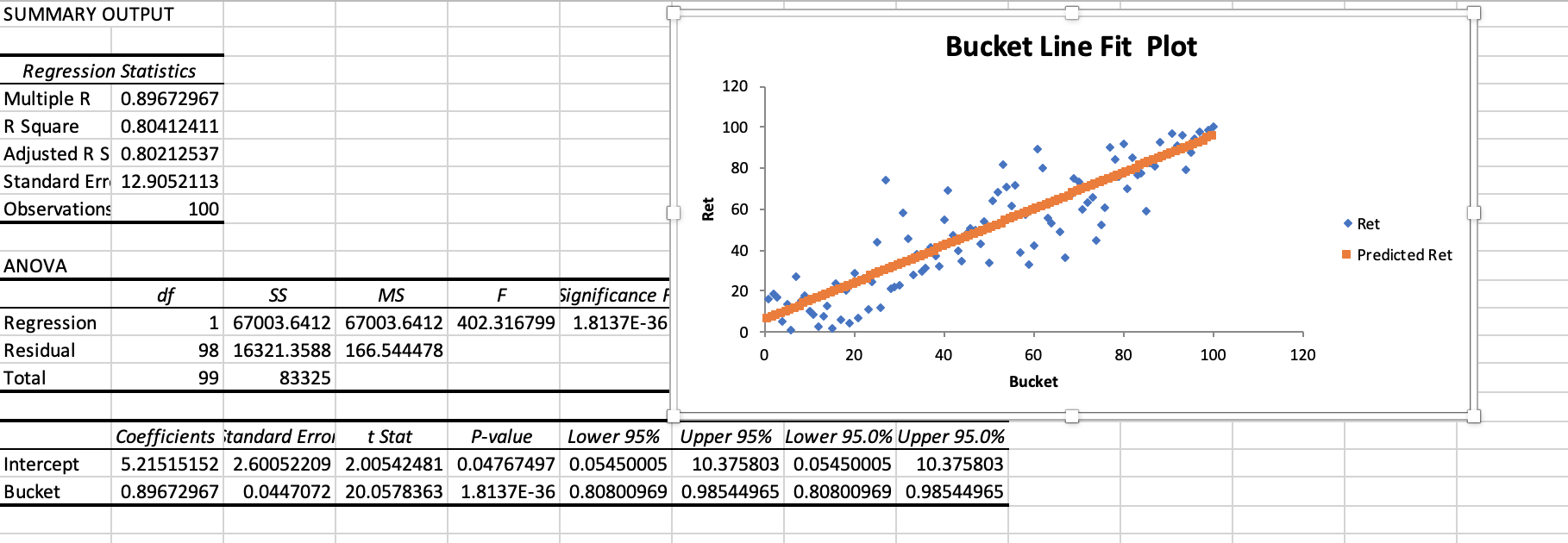
If you do a 100 bucket rank performance test then sort and rank the RETURNS and run this through an Excel spreadsheet you can get the Spearman Rank Correlation and the significance of this. This is a non-parametric test and it mainly avoid the problem of outliers. But also problems with non-linearity etc.
Here is a screenshot of a multi-factor ranking system. There are other ways to do this and regular correlations (not Spearman) may work as well generally. Spearman does not pay me to promote his method.
But again thank you for your post. I might start insisting that a factor pass both tests or at least know which buckets my ranking system is closing so that I can decide which method to use for rating that factor.
I agree that good factor design should be the core of any factor based investment strategy.
The factor in question is IsNa(LoopSum(“Eval(GrossProfit(CTR, qtr) >= GrossProfit(CTR+4, qtr), 1, NA)”, 16, 0, 1, FALSE, TRUE) , 0), which intends to look at the persistence of GrossProfit Growth over the past 16 years.
I found that when looking at ‘long term’ metrics, it works better to look at broader periods (annual or ttm as opposed to qtr), probably because they are bit more robust. But that is just my current interpretation and it might change.
Back to the topic of this discussion: I’m still interested to hear more about how other people ‘rank’ their individual factors.
I’m trying to fully understand the content of your post. Let me try to put it in my own words. Most likely I have not fully interpreted it the way you intended it and please let me know if that is indeed the case.
Currently, you mainly use the time-series data of the top buckets results of your factors to run linear regressions (available from the ‘performance’ tab in the ranking environment of portfolio123). You run a t-test to test whether the returns of those top buckets differ significantly from the returns of a randomized universe (your benchmark). You can do this, for example in Excel.
In case you would do that for the factor I showed you (mentioned in my previous post in reaction to Jones) this would work out as expected in your current process, as the top ranking factors would not achieve positive risk adjusted returns compared to the benchmark. Hence, the factor would not be considered as a part of your multifactor regression model, because it is not powerful enough on its own. For this reason, you would not often find yourself asking the question that I presented here (because you mainly focus on the performance of the top buckets).
If a factor indeed passes your test first test, you will add it to your current multifactor regression model and see if it increases risk adjusted performance there, as is done many times in academic literature.
However, you note that such a procedure might not take into account all relevant information (as it does not so much take into account the relationship between all quartiles of a factor with past returns). Because of this, you now suggest using the Spearman Rank Correlation as a metric (in addition to the Pearson Correlation coefficient that I intended to mentioned above) to score a single factor ranking system.
I will have a look at the Spearman Rank Correlation as a metric and check out what it would alter in my factors rankings. Thank you for that :). If you have any other suggestions, please let me know. I bet any user of Portfolio123 runs into the question of which factor is ‘good enough’ to add and which is not.
By the way, I’m guessing the mention of Spearman not paying you is your sense of humor, as Spearman has been lying under the ground for quite some time now (Charles Spearman - Wikipedia).
One thing that this discussion does not address, but which you should keep in mind, is that some factors don’t perform well on their own but help other factors a great deal. The obvious example is size factors, whose performance, when transaction costs are taken into account, are terrible, but if used in a ranking system, will tend to make overall results better. A less obvious example is accruals. In most bucket tests, an accrual formula will look pretty bad. But if you’re using earnings as a factor (e.g. ROE, EPS growth, P/E), then taking accruals into account will help weed out companies whose net income is greater than their operating cash flow on a relative basis (compared to, say, total assets, and compared to other companies). There are a wide variety of accrual formulas out there, but none that I’ve encountered do well on bucket tests. They have, however, improved performance of my ranking systems as a whole.
I use single-factor bucket tests a lot, and the measures you are discussing are very valuable, especially when comparing similar factors. But multi-factor ranking systems aren’t just collections of factors thrown together willy-nilly, and a ranking system’s performance is not necessarily going to correlate with the performance of its individual factors. A multi-factor ranking system is a system above all, and all its parts move together.
It’s a case of not seeing the forest for the trees. If you spend a lot of time examining each tree, you’re not going to get a sense of how the forest works. Trying for precision in ranking system weights is mostly a waste of time. If you have a ranking system you’re happy with and you change the weights a little, you’re still choosing most of the same stocks. Personally, I waste a lot of time with this stuff. It’s fun, and maybe it improves my results a little bit, and it satisfies my obsessive-compulsive math-nerd proclivities. But I wonder whether, if I didn’t waste so much time assigning precise weights and instead focused on how a ranking system works as a whole–not its performance so much as its functionality, in a non-measurable sense–I might be better off.
Thank you, Yuval for your contribution. I definitely had some of what you are writing in mind when I started this topic. Note also my mention of “you now want to rank those ‘direct’ factors (so excluding marketcap and accrual type factors that have more of a augmenting nature)”, which was pretty much a direct reference to your classification of direct factors vs augmenting factors (as mentioned here: The 3 Types Of Factors | Seeking Alpha.
I wasn’t planning on sharing this, but as this discussion is going a bit further now, I will do so anyway.
What I’m working on currently (and what I think is related to your reply) is answering the question of: “Should this factor be added to my multi factor ranking systems?”.
The process in my mind goes as follows:
(1) Gather a whole bunch of factors that I think make financial sense. Of all those factors (including the augmenting ones) run single factors ranking tests and test them all based on one or more metrics (the topic of this discussion). In this step, the augmenting ones will of course not have a good chance to rank high, so let’s keep those in mind. Next, (2) rank them all and (3) create a correlation matrix of all factors using the historical time series data similar to what you described here: non correlated factors - #2 by yuvaltaylor (again, maybe taking an other metric into account as opposed to just the slope to determine the correlations) . After that (4) use a clustering algorithm (without going too much in depth, I’m currently looking at something simple and basic like this: Create clusters using correlation matrix in Python - Stack Overflow) to make x different clusters and pick the y top factors from each ‘correlation cluster’. You now have x*y amount of factors in your ranking system. The correlation makes sure that you, let’s say, at least somewhat take into account the dynamics of the forrest as a whole instead of staring blindly at the biggest trees in the forrest the whole day.
(5) After that - and this brings me to your input - add back, one by one, any other factors that you started with and made financial sense to you (these are the ‘least effective’ direct factors, some potentially augmenting factors like marketcap and accruels and of course, some factors that maybe seemed to make financial sense to you but don’t show a lot of promise in practice. The augmenting factors will pop up - or at least that is my idea - and will augment the other factors such that the ranking system as a whole will score higher on the metric as described under step (2).
With such a system in place (or a similar but better one), whenever I find a new factors, I just add the new factors to the starting step (1) and follow the other steps to see if it adds value. Of course assuming the testing takes place with multiple randomly generated universes and over different time periods.
As I have some ocd-nerd qualities myself as well, I will most likely do this using the portfolio123 API.
Apart from your process of determining metrics to ‘judge’ a single factor ranking system, I would be very interested to hear your thoughts on researching the changing dynamics of a ranking system as a whole. I was hoping that the results of the process I described above would give me at least some insights into that as well, and won’t be just a big framework of optimisation and data-mining, which is an easy trap to fall into.
Take a look at the attached spreadsheet that someone on P123 posted about 1y ago. I have been keeping the list of factors up to date. I use it with API to generate a list of performance on buckets (20). Look at the Charts tab for an example of how the “winning” factors can be selected based on slope, weight, etc. Its a good start and has been working for me.
I think what you say about the interaction of factors is obviously true. You point out that a factor that could be helpful because of its interaction with other factors might be missed by the above method.
I would only add that IT CAN ALSO WORK IN REVERSE. You can have factors that work well individually but cause problem together.
For example, PrW52%ChgInd, PrW26%ChgInd and Pr13W%ChgInd maybe be found to be good candidates as factors for a particular universe and a ranking system using the above methods. Add one of these factors to a ranking system and the returns might improve. All good.
But at least with some ranking systems and universes adding all three of these factors can hurt your returns. AND INCREASE THE DRAWDOWNS.
I am not sure that one can ever be absolutely sure why this is or even confirm it for their own universes and factors but like Yuval I try to think of a story to explain this. Perhaps an industry that has excelled for for 52 weeks 26 week and 13 weeks is due for some mean-reversion. Especially in a general market drawdown (increasing the drawdowns).
@Victor1991. Your method is reminiscent of the Step-Forward approach used for linear regression models. Good for finding factors that interact in a positive way.
But maybe you need to do a step-backward approach to make sure that you do not already have factors in your system that are interacting in a negative way.
But then if you do step-backward and then step-forward is that a guarantee that you have all of the positively interacting features and removed all of the negatively interacting features? Maybe one could do this with multiple iterations.
Still no guarantee whatsoever, I think. Your success with this method will depend on the order of adding and subtracting factors. But doing it once would be a start and would not be a bad idea, I think.
Back in the day when linear regression and step-backward and step-forward was talked about more this was often automated and regressions happen quickly on computers. It was doable in a day.
I love P123’s optimizer but there are not enough seconds in the rest of the life of the universe to get it exactly right using P123’s optimizer. We have not even mention the 6-unviverse method of cross-validation that many are fond of.
Boosting and Neural-nets are great at finding interactions. Too good sometimes and there will need to be some cross-validation for these methods to work out-of-sample.
Hmmm…… Not trivial to get that right and maybe we have opened Pandora’s box—making it too easy for anyone to compete… But the cat is probably already out of the bag (mixing metaphors I know).
For now, I think Yuval, and many P123 members (including you and perhaps me) have some pretty good ways of doing it manually. I am more impressed with the similarities than the differences in what we do. There are clear differences in approaches. There has to be the case with the time-constraints we have with manual or even automated methods. That is what makes a market: we cannot all agree and hope to make money. So that is to be celebrated.
TL;DR I like your approach and would not really suggest changing anything. But no method will be perfect with the time constraints with manual and even automated methods.
What you've described sounds like a very well-thought-out procedure to me.
I don't really have many thoughts on "researching the changing dynamics of a ranking system as a whole." I realize that factors go in and out of favor. Sometimes there are simply no value factors or low-vol factors or momentum factors that work (though quality factors almost always work). Periods like those tend to be relatively short, but there was a years-long period pretty recently in which almost no value factors worked at all. This summer I tried reweighting my ranking system based on three-month factor momentum: if value factors were out of favor over the last three months, they'd get lower weights, and if they were in favor, they'd get higher weights. The result was disastrous. I lost a lot of money in transaction costs, and even if I hadn't, I would have been better off sticking to my original weights. My conclusion is that the effectiveness of factors varies a huge amount from month to month and the correlation between the past and the future is very low. The best approach to ranking system design is to think long-term. Would such-and-such a system have worked pretty consistently over the last ten to fifteen years? I find myself drawn to systems that consistently outperform (like a simulation with excess returns every year) over systems with high overall CAGR but variable performance.
I'm curious how well your clustering is going to work. I hope it works out better than that of the authors of "Is There a Replication Crisis in Finance." For me, it's quite intuitive to classify factors into seven groups: growth factors are those that compare a recent number to some prior numbers and privilege growth in the value over time; stability factors are those that do the same but privilege average or similar values, and also include other factors that result in low volatility; value factors compare something about the company to its price and favor lower price and higher "something"; technical factors look at the change in a stock's price and/or volume; size factors privilege smaller over larger companies; quality factors are fundamental-based factors that don't fit into the other categories; and sentiment factors are based on analyst estimates, recommendations, short interest, insider ownership, and institutional ownership. Whether that's better than what you'll get from clustering I don't know and am curious to find out.
I just wanted to add that I have learned a lot from the discussion in this thread—from both you and Yuval.
Yuval clearly makes a valid point about interactions. After thinking about it over-night, I think I will be using the step-backward approach. This idea was prompted by our discussion—so again, thank you for your post.
I will remove a factor, re-optimize the system on a training sample and see if this improves the result on a test sample. I will do this for each factor for the first round. I will keep the ranking system that improved the returns the most after the removal of a single factor ( if there is an improvement). I will then repeat until there is no longer any improvement by removing a single factor.
I do not mean to imply that anyone’s else’s methods might cause over-fitting—especially if they are cross-validating but I do think adding an endless list of factors that are not already significant on their own is certainly MORE PRONE to over-fitting. Is that debatable?
Keep in mind that over-fitting the stock market is FAR DIFFERENT than over fitting the usual data for machine learning.
Over-fitting for machine learning involves fitting to noise for an independent and identically distributed (i.i.d.) random variable. Even if it were i.i.d. there is a lot of noise in stock market data. But it gets worse.
Because the stock market is not stationary and not i.i.d. we all over-fit no matter what we do.
De Prado puts it a simpler way. The stock market has “regimes” and because we are fitting to regimes in the past (that will never be repeated exactly in the future) we are always overfitting.
The step-backward method above is not so computer intensive that it cannot be done and is less likely to lead to over-fitting than the step-forward method, I believe.
For clarity of the above about how long testing all of the interactions could take, if you decide to have a ranking system with 60 factors and you are going to try 100 factors to see which 60 factor system is best (with the most favorable interactions) there are 1.374623414 E+28 ways to do a 60 factor ranking system. 1.374623414 E+28 ways to select 60 different things out of 100 things (by the mathematical definition of combination). n!/r!(n-1)! for anyone who wants to verify this at home. ! is the symbol for factorial.
For comparison there have been 4.36E+17 seconds in the universe so far!!!
Even if a demon had finally worked out which factors to use here today, she would still have to start on weighing each factor.
Human experience and discretion could obviously reduce this number. I am not saying we should not be spending some time on a computer and/or a spreadsheet using discretion as well as multiple trials and some statistics. I am saying that that however I do it–even using some discretion–I am guaranteed to never arrive at the optimal solution.
I will be making compromises between a better solution and the time it will take to arrive there whether I like it or not. I hope to make those compromises consciously whenever I can. I can only assume Marco will be making some decisions regarding efficient use of computer time as well: it is difficult to get away from.
There’s a lot of interesting ideas in this thread, and Jim has an excellent post on Oct 13 about Spearman rank correlation which resonates a lot with how I think about ranking systems.
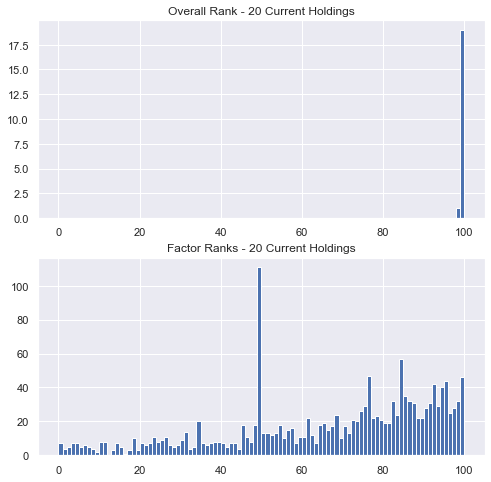
As an exercise, look at the current holdings for one of your ranking systems. Plot the overall rank of each stock as well as the distribution of rankings for each factor within the system, again for your current holdings only. Here’s what one of mine looks like.
For most systems, you’re likely trading from the tails of the overall rank distributions but from the bellies of the factor rank distributions. Of course this can vary – if you carry more positions, have longer holding periods, etc., but in general, this leads me to evaluate ranking system performance differently from factor performance.
For ranking system performance, looking at the performance of the top bin, or the top few bins, is most helpful for me. But when evaluating a factor, I usually want to know if a higher factor rank will tilt me towards higher overall return, and that’s exactly what the Spearman rank correlation measures: whether there is a monotonically increasing relationship between factor rank and return rank. Of course, other metrics can be useful for factors too, looking at top minus bottom quantile performance for example, but as the histogram above shows, we’re not usually holding the top (or bottom) stocks for individual factor ranks.
Personally, I’d find it very useful if the rank correlation were included in the Rank Performance and Ranking System Optimizer outputs.
I wanted to follow up on some of the procedures that I described above. I have ran my described procedure on variations of the the Easy to Trade US and Easy to Trade Europe universes.
Apart from my own factors and some I found on the forum earlier, I used the top factors of this list as well to test the procedure, so thank you for that.
I ended up using a metric based on your ultimate omega ratio as well as your outlier trimmed alpha measure for both single factors as well as multi-factor ranking systems, which I calculated for each of the equity curves. The metric I used for single factor rankings was
with a maximum score of 5. I used the same for the multifactor rankings but multiplying the benchmarks return by 5 instead of 2 for the last term. Taking the two rankings based on the omega ratio and outlier trimmed alpha using the above measure and summing these rankings gave a good idea about the consistency of the performance of the single and multi-factor ranking systems.
Using the clusterings algorithm I linked earlier I get 6 clusters for both US and European data.
Cluster 1 roughly consists of Growth and Quality factors
Cluster 2 is rather small and consists of Growth, Quality and Valuation factors
Cluster 3 roughly consits of Growth, Quality and Value and Stability Factors
Cluster 4 roughly consists of Growth, Quality, Valuation, Stability and Sentiment Factors
Cluster 5 consists of Size, Stability and Quality Factors
Cluster 6 consists of Momentum and Sentiment Factors
Needless to say, I did not find the intuitive results I had hoped for using this clustering method.
Moreover, following the rest of the procedure I described above I found another shortcoming. Because one of the clusters is so small (Cluster 2), the amount of factors to be picked from each cluster needs to remain small or Cluster 2 will be deluted in some way or another.
Hence, I decided to change this step for now to (4) determine the highest correlation of each of the ranked factors with the factors that are ranked above and pick the top 100 factors that have a correlation less than 0.85 with factors ranked above that factor.
Following that procedure I obtained an equally weighted 100-factor ranking system that outperformed the benchmark over the past 20 years by about 35% before slippage. Which I thought was not bad. The results held up across different universes.
Most interesting was this step. Adding the factors one by one, I found that for this specific multi-factor ranking system Return on Capital factors were pretty much always added. Also, Accruel and Size factors were also almost always added to improve returns. This leads me to believe my ranking systems should give more than equal weighting to Return on Capital factors and should always consist of one or more augmenting factors. So these results were quite intuitive in my opnion.
I decided to add another step (6) to remove factors one by one after adding all the ones from step (5). Factors that were removed were mainly direct factors (non size and accruels) that were at least somewhat related to other direct factors (For example one of the sales growth factors was removed, but the gross profit growth factor of the same form that ranked higher initiually was kept. I thought the results of this step were also quite intuitive.
I ended up with 180 factors that combined resulted in an annual alpha of about 40% above the benchmark. For European stocks the results were even better (+50%), also across different randomized universes. The results were also pretty consistent year by year, with hardly any negative years besides during the GFC.
I took this post to heart in constructing the metric I described above. I do want to mention though, that I think that even though for multi-factor ranking systems you only utilise the top bucket in your simulations, it is still very valuable for a model to explain the full cross-section of stock returns, just to be more confident about your out-of-sample results. I don't think I would ever chose a multifactor ranking system based on the performance of the top bucket alone (if we can speak of such a thing anyhow, with the variety of buckets that can be applied).
I might share the python code of the above procedure at some point in the future once I clean it up a bit.
I like this a lot, Victor. I like the way you’ve drawn on different people’s comments and advice, the way you’ve balanced intuition and backtesting, and the results you’ve obtained.
This seems to bee a very good framework for testing and building a multifactor system. I'm trying at the same method, but to be able to compare, what settings did you test the two universes (volume, price, rebalancing, etc.) and which universes did you test?