I find myself asking what Billy Beane would do. As you know Billy Beane—as played by Brad Pitt in the movie Moneyball—produce a winning baseball team by using statistics to help with decisions about player recruitment. This is based on the real-life Billy Beane. If I could be as successful as Billy Beane and as cool as Brad Pitt…….
Note: Marc was the first person to make the analogy of what we do to Moneyball. I am hoping he will not mind me borrowing this analogy if I give him the credit he deserves.
I came across this free PDF about predicting future batting averages for a player (or the ‘True batting average’). Link here:[url=https://gumroad.com/l/empirical-bayes]https://gumroad.com/l/empirical-bayes[/url]
The author of this PDF asks the question: who is the best batter? All of you who follow baseball know that the best batters are: Jeff Banister, Doc Bass, Steve Biras, C.B. Burns, and Jackie Gallagher.
These are the players with perfect batting averages and therefore must be the best players, right?. And they must be in the hall of fame, right? Never mind that these players all had only one or two at bats.
Hmmm. Best batting average but not necessarily the best batters—and no they are not in the Baseball Hall of Fame for hitting. We all make an adjustment with small samples naturally. Is there a quantitative way to make such an adjustment?
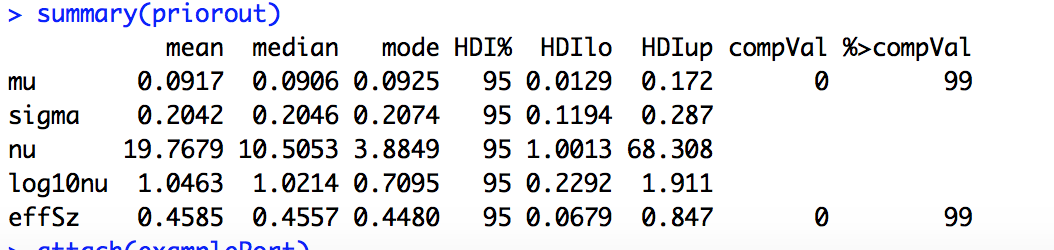
The PDF uses Empirical Bayesian Statistics to determine what the true abilities of the players in the major league are. And he answers the burning question: does Hank Aaron belong in the Hall of fame? I think it is worth a read to give a better gut-feel on how to make adjustments for outliers, small samples, cherry-picked data and the multiple comparison problems. This PDF is readable. Just ignore and details about the beta function. I refer you to “Doing Bayesian Data Analysis” by Krutschke for a more detail example of batting averages and Hierarchical Bayesian Analysis wth multiplies levels. Multiple levels are good for questions like: what if the player is a pitcher?
This can be done with stock returns too. I will go through the rest quickly.
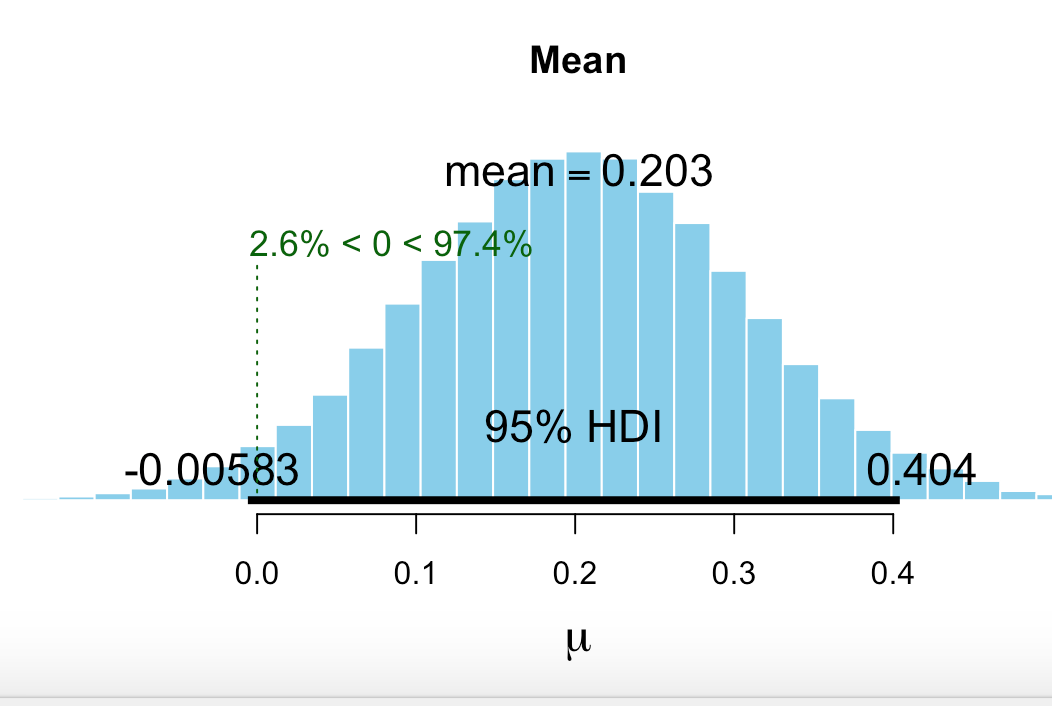
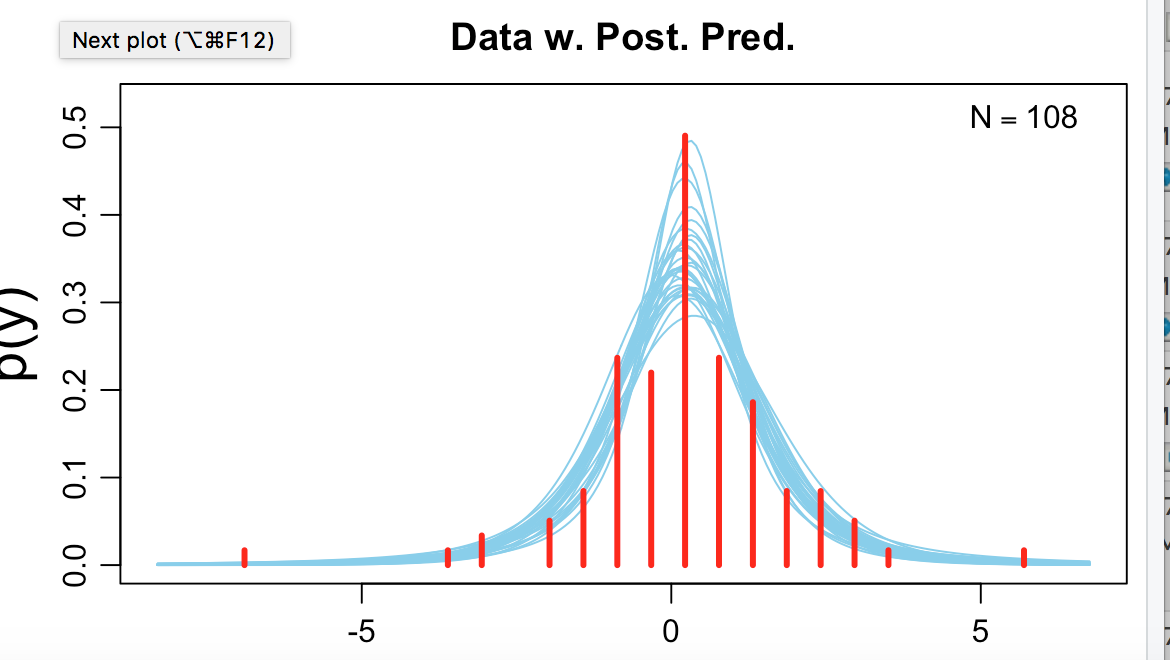
The PDF develops a prior for batting averages. I develop a prior by finding the weekly averages for all of my ports including a number of unfunded auto ports. See first image for the t-distribution for the prior generated by BEST in R.
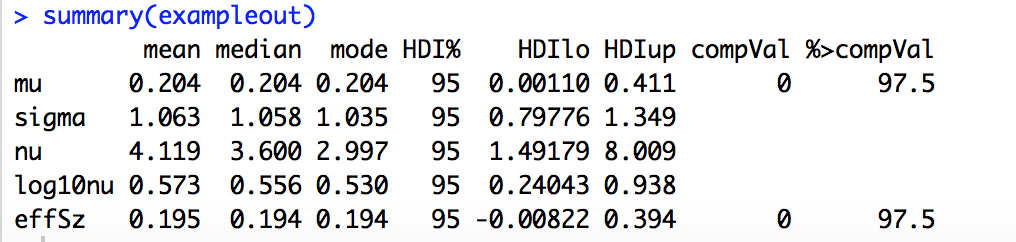
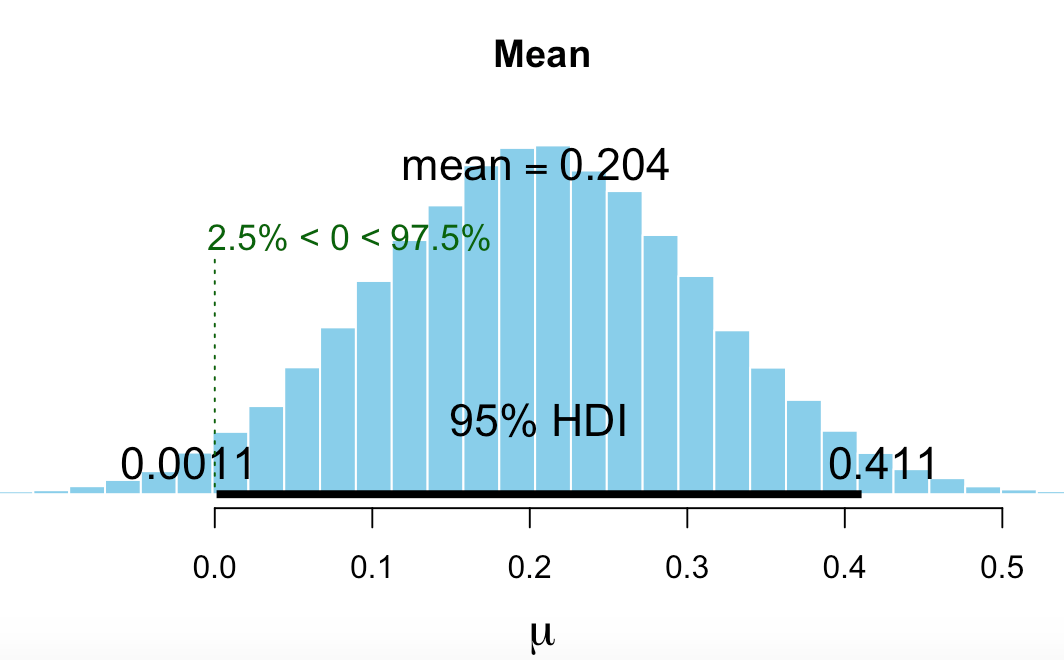
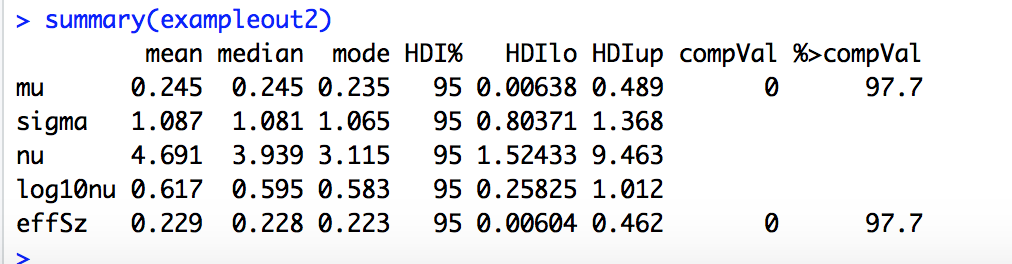
The PDF then generates the posteriors for the players including Hank Aaron. Billy Beane could have had to decide whether to add Hank Aaron to the team (or how much to offer him). I have to decide whether one of my auto ports should be funded. See the posterior probabilities for excess returns for one of my auto ports.
The most credible value for excess returns is 11% for the port (annualized). The 95% credible interval just barely includes zero.
You can make your own judgement but only 11% better than the benchmark and not quite significant based on the 95% credible interval? Hmmm… Using the prior for this port did not cause a huge correction (shrinkage in the Bayesian parlance) for this port but it did for the ones with more extreme excess returns.
What would Billy Beane do? Maybe not this exactly. But he would not pay a lot for Doc Bass’ batting skills. And he would use something like this: he wouldn’t just relying on his gut, I think.
This could be adapted to selecting Designer Models with objective criteria for selection.
-Jim