Here are rolling three year returns:
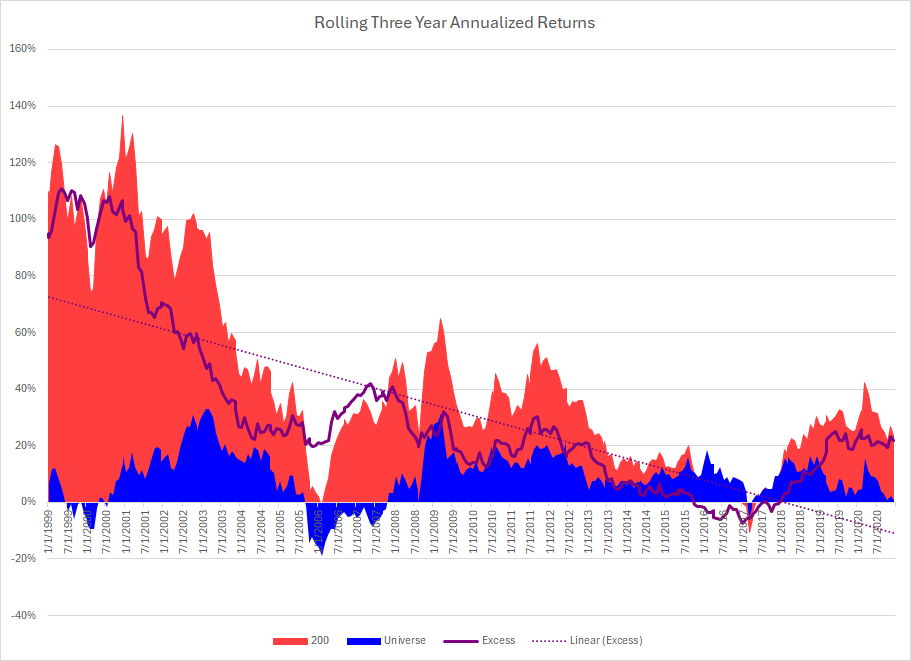
Notes:
This was a very popular public system that was designed in 2008 or so. Notice the drop off out of sample.
Notice also that the system stopped producing excess returns from 2015 - 2018.
My sense is that too much money was eventually put into this system; causing huge collective slippage. Once people stopped using it, the results bounced back to the prior out of sample period.