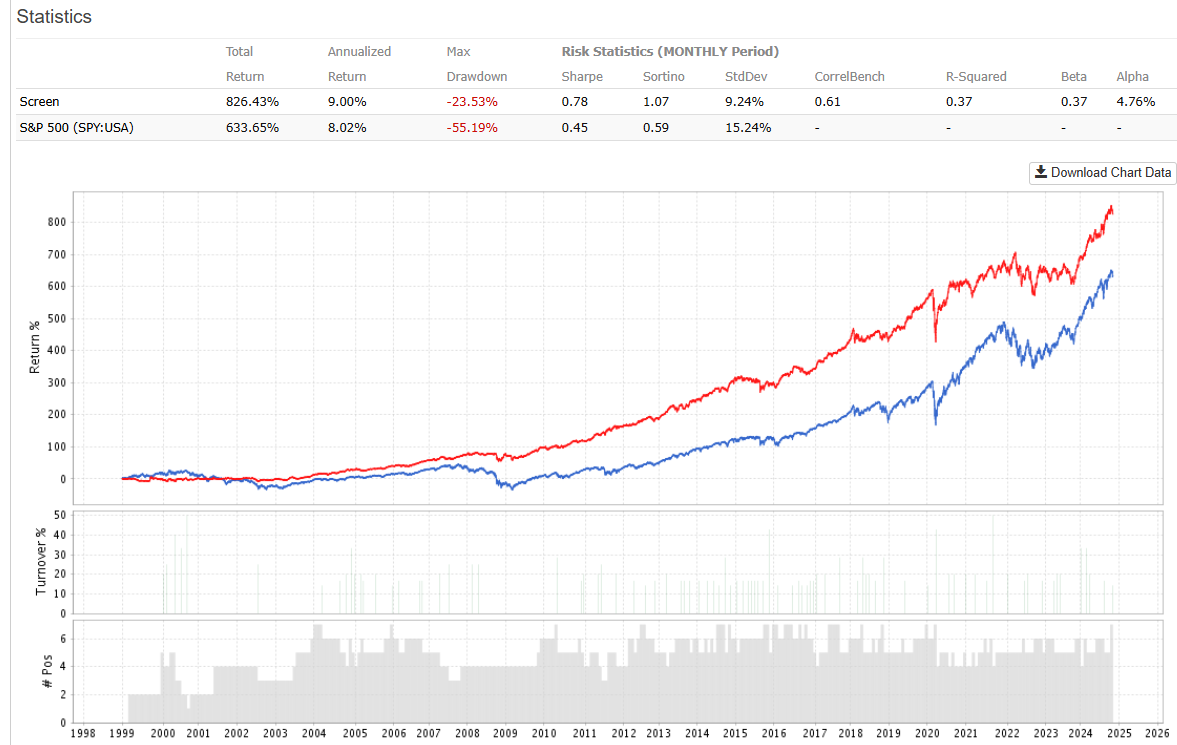
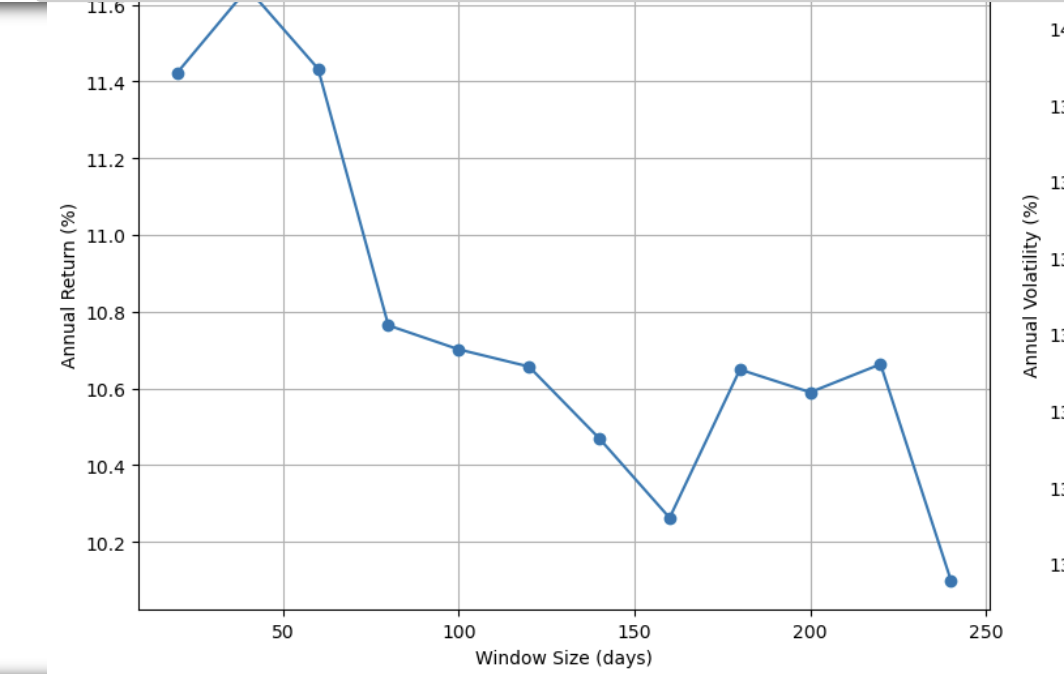
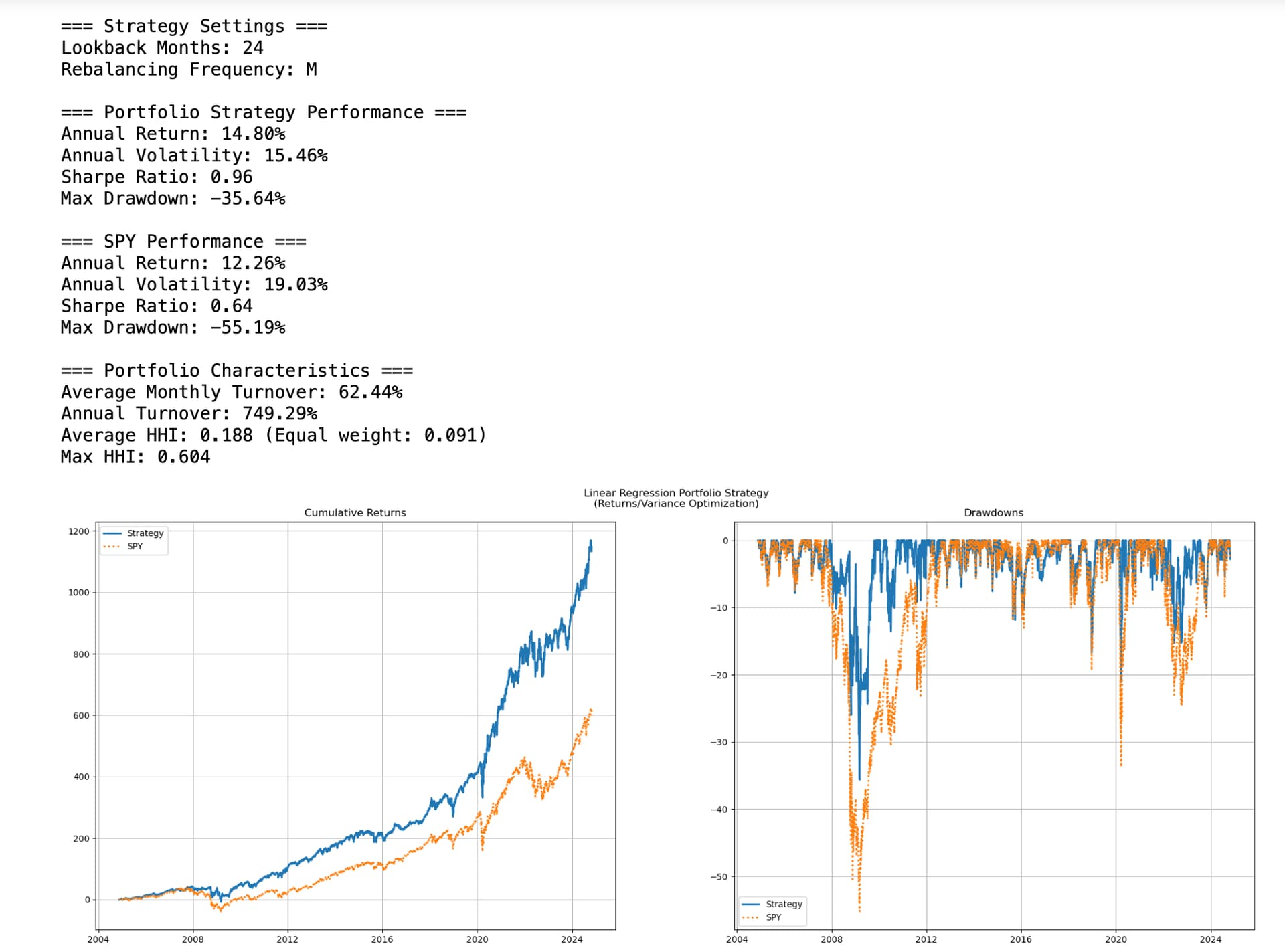
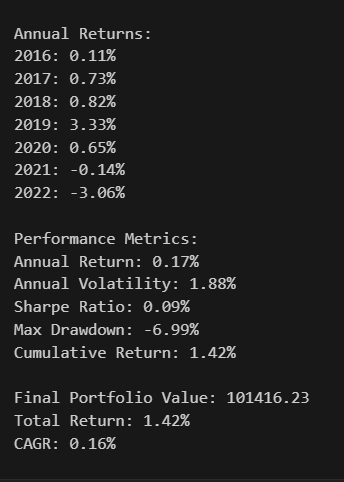
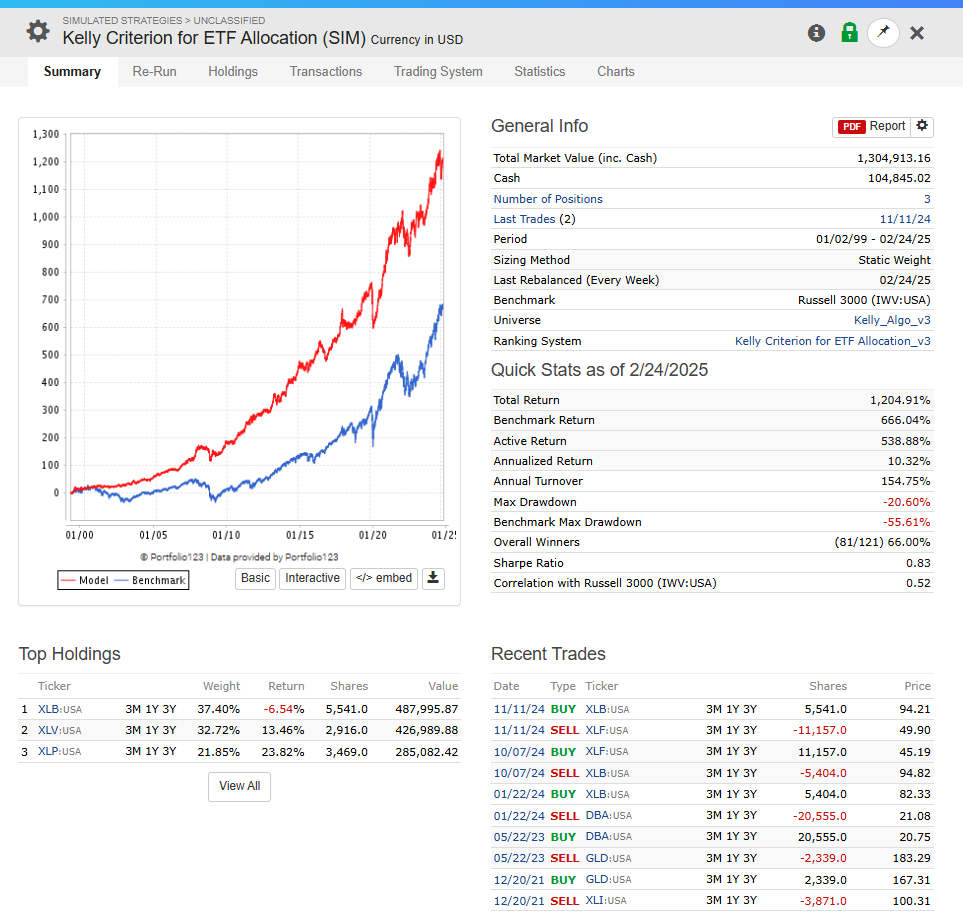
Kelly Betting is best know for optimizing returns. But it can also be used to control risks.
The general formula for Kelly betting is edge/odds.
I used (Probability of beating SPY)/Variance for 10 ETFs (Nine SPDRS and TLT). with a sliding 60 trading day window, rebalancing monthly.
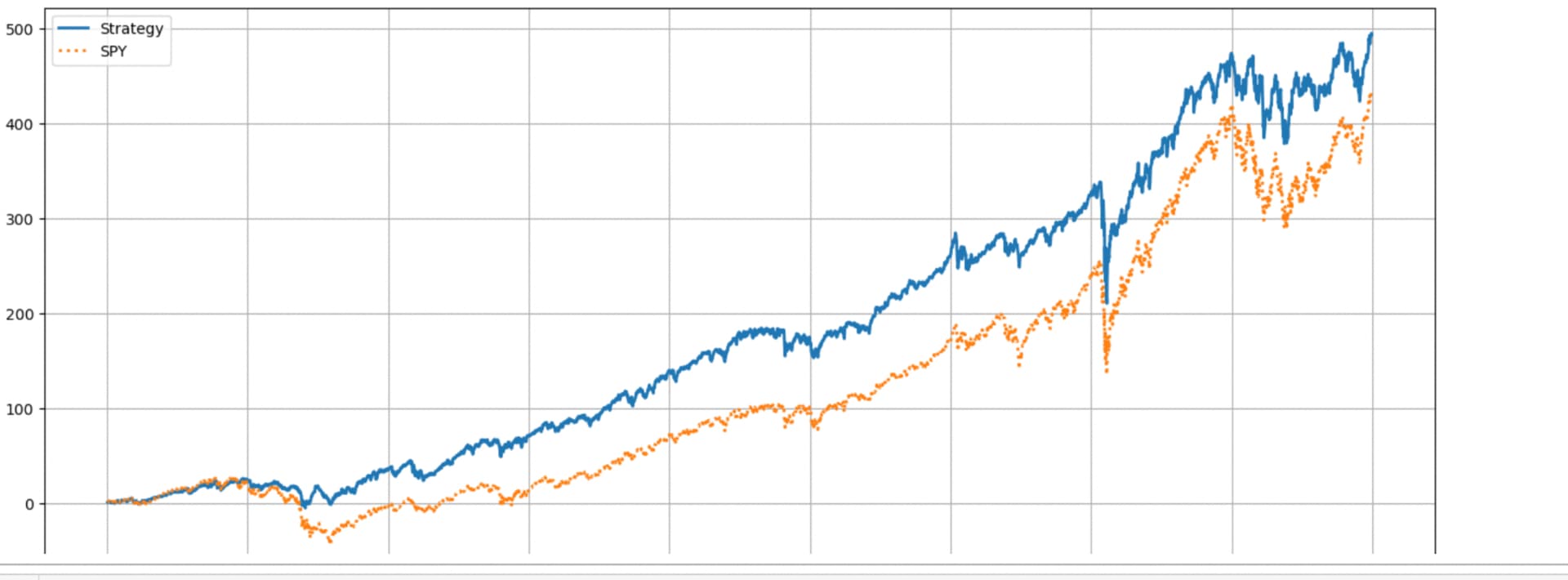
It did reduce risk (especially drawdown in 2008) with little loss in returns. Some could consider using some leverage to get closer to "Optimal Kelly."
The results:

The code for those interested. You may have to use" !pip install yfinance" in a cell but it should run after doing this. You can change the parameters and the ETFs after that if you wish:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import yfinance as yf
from tqdm import tqdm
class MultiStockBPW:
def __init__(self, stock_tickers: list, benchmark: str = "SPY", n_bootstrap: int = 1000,
window_size: int = 60, rebalance_freq: str = 'M'):
self.stock_tickers = stock_tickers
self.benchmark = benchmark
self.n_bootstrap = n_bootstrap
self.window_size = window_size
self.rebalance_freq = rebalance_freq
def prepare_data(self, start_date: str, end_date: str) -> tuple:
"""Download and prepare return data for all stocks and benchmark"""
print("Downloading data...")
# Download benchmark data first
bench_data = yf.download(self.benchmark, start=start_date, end=end_date, progress=False)
if bench_data.empty:
raise ValueError(f"No data available for benchmark {self.benchmark}")
# Initialize returns DataFrame with benchmark
all_returns = pd.DataFrame(index=bench_data.index)
all_returns[self.benchmark] = bench_data['Adj Close'].pct_change() * 100
# Track which stocks have valid data
valid_stocks = []
# Download stock data
for ticker in tqdm(self.stock_tickers, desc="Downloading stocks"):
try:
stock_data = yf.download(ticker, start=start_date, end=end_date, progress=False)
if not stock_data.empty:
returns = stock_data['Adj Close'].pct_change() * 100
# Check if we have enough data
if len(returns) >= len(bench_data.index) * 0.5: # At least 50% of benchmark data
all_returns[ticker] = returns
valid_stocks.append(ticker)
else:
print(f"Insufficient data for {ticker}, excluding from analysis")
except Exception as e:
print(f"Error downloading {ticker}: {e}")
if not valid_stocks:
raise ValueError("No valid stocks found")
print(f"\nUsing {len(valid_stocks)} stocks: {', '.join(valid_stocks)}")
# Drop any remaining NaN values
all_returns = all_returns.dropna()
return all_returns, valid_stocks
def bootstrap_excess_returns(self, historical_excess: pd.Series) -> float:
values = historical_excess.values.flatten()
bootstrap_samples = np.random.choice(
values,
size=(self.n_bootstrap, len(values)),
replace=True
)
bootstrap_means = np.mean(bootstrap_samples, axis=1)
return float(np.mean(bootstrap_means > 0))
def calculate_weights(self, data: pd.DataFrame, valid_stocks: list, window_start: int, t: int) -> pd.Series:
"""Calculate weights based on probability/variance ratio"""
stock_metrics = []
for stock in valid_stocks:
# Get historical data for this window
stock_returns = data[stock].iloc[window_start:t]
historical_excess = stock_returns - data[self.benchmark].iloc[window_start:t]
# Calculate probability of beating benchmark
prob = self.bootstrap_excess_returns(historical_excess)
# Calculate variance
variance = stock_returns.var()
# Handle zero variance case
if variance == 0:
ratio = 0
else:
ratio = prob / variance
stock_metrics.append({
'stock': stock,
'prob': prob,
'variance': variance,
'ratio': ratio
})
# Create DataFrame for better visibility of the metrics
metrics_df = pd.DataFrame(stock_metrics)
# Calculate normalized weights
total_ratio = metrics_df['ratio'].sum()
if total_ratio > 0:
weights = pd.Series(
[metric['ratio'] / total_ratio for metric in stock_metrics],
index=valid_stocks
)
else:
# If all ratios are zero, use equal weights
weights = pd.Series(1.0 / len(valid_stocks), index=valid_stocks)
return weights
def run_strategy(self, data: pd.DataFrame, valid_stocks: list) -> pd.DataFrame:
"""Run the modified multi-stock BPW strategy with periodic rebalancing"""
print("Running strategy...")
n_stocks = len(valid_stocks)
# Initialize weight matrices
stock_weights = pd.DataFrame(0.0, index=data.index, columns=valid_stocks)
portfolio_returns = pd.Series(0.0, index=data.index)
# Get rebalancing dates
rebalance_dates = pd.date_range(
start=data.index[0],
end=data.index[-1],
freq=self.rebalance_freq
)
# Only keep dates that exist in our data
rebalance_dates = rebalance_dates[rebalance_dates.isin(data.index)]
# Use equal weights until we have enough data for the first window
initial_periods = max(self.window_size, 4)
initial_weight = 1.0 / n_stocks
first_rebalance_idx = data.index.get_loc(rebalance_dates[0])
stock_weights.iloc[:first_rebalance_idx] = initial_weight
# Calculate initial portfolio returns
for t in range(first_rebalance_idx):
portfolio_returns.iloc[t] = (stock_weights.iloc[t] * data[valid_stocks].iloc[t]).sum()
# Main strategy loop - only compute new weights on rebalancing dates
current_weights = pd.Series(initial_weight, index=valid_stocks)
# Track metrics for analysis
metrics_history = []
for t in tqdm(range(first_rebalance_idx, len(data)), desc="Computing strategy"):
current_date = data.index[t]
# Update weights if this is a rebalancing date and we have enough history
if current_date in rebalance_dates and t >= initial_periods:
window_start = max(0, t - self.window_size)
current_weights = self.calculate_weights(data, valid_stocks, window_start, t)
# Store metrics for this rebalancing period
metrics = {
'date': current_date,
'weights': current_weights.to_dict()
}
metrics_history.append(metrics)
# Set weights for this period
stock_weights.iloc[t] = current_weights
# Calculate portfolio return using current weights
portfolio_returns.iloc[t] = (current_weights * data[valid_stocks].iloc[t]).sum()
results = pd.DataFrame({
'returns': portfolio_returns,
**stock_weights
})
# Add metrics history to results
results.attrs['metrics_history'] = metrics_history
return results
def analyze_portfolio(self, start_date: str, end_date: str):
"""Run complete portfolio analysis"""
try:
# Prepare data
data, valid_stocks = self.prepare_data(start_date, end_date)
# Run strategy
results = self.run_strategy(data, valid_stocks)
# Calculate number of rebalances
rebalance_dates = pd.date_range(
start=data.index[0],
end=data.index[-1],
freq=self.rebalance_freq
)
n_rebalances = len(rebalance_dates[rebalance_dates.isin(data.index)])
# Calculate cumulative returns for drawdown analysis
cum_strategy = (1 + results['returns']/100).cumprod()
cum_benchmark = (1 + data[self.benchmark]/100).cumprod()
# Calculate drawdowns
rolling_max_strategy = cum_strategy.expanding().max()
rolling_max_benchmark = cum_benchmark.expanding().max()
drawdown_strategy = (cum_strategy - rolling_max_strategy) / rolling_max_strategy * 100
drawdown_benchmark = (cum_benchmark - rolling_max_benchmark) / rolling_max_benchmark * 100
# Calculate performance metrics
strategy_returns = results['returns']
benchmark_returns = data[self.benchmark]
# Annualized returns (using 252 trading days)
strategy_ann_return = (1 + strategy_returns.mean()/100)**252 - 1
benchmark_ann_return = (1 + benchmark_returns.mean()/100)**252 - 1
# Annualized volatility
strategy_ann_vol = (strategy_returns/100).std() * np.sqrt(252)
benchmark_ann_vol = (benchmark_returns/100).std() * np.sqrt(252)
# Sharpe ratios (assuming 0% risk-free rate for simplicity)
strategy_sharpe = strategy_ann_return / strategy_ann_vol
benchmark_sharpe = benchmark_ann_return / benchmark_ann_vol
# Print performance summary
print("\n=== Strategy Settings ===")
print(f"Window Size: {self.window_size} trading days")
print(f"Rebalancing Frequency: {self.rebalance_freq}")
print(f"Total Rebalances: {n_rebalances}")
print("Weighting Method: Probability/Variance ratio")
print("\n=== Portfolio Strategy Performance ===")
print(f"Annual Return: {strategy_ann_return*100:.2f}%")
print(f"Annual Volatility: {strategy_ann_vol*100:.2f}%")
print(f"Sharpe Ratio: {strategy_sharpe:.2f}")
print(f"Max Drawdown: {drawdown_strategy.min():.2f}%")
print(f"\n=== {self.benchmark} Performance ===")
print(f"Annual Return: {benchmark_ann_return*100:.2f}%")
print(f"Annual Volatility: {benchmark_ann_vol*100:.2f}%")
print(f"Sharpe Ratio: {benchmark_sharpe:.2f}")
print(f"Max Drawdown: {drawdown_benchmark.min():.2f}%")
print("\nFinal Portfolio Weights:")
for stock in valid_stocks:
print(f"{stock}: {results[stock].iloc[-1]:.2%}")
# Plot results
fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 18))
fig.suptitle(f'Multi-Stock BPW Strategy (Prob/Var)\n(Window: {self.window_size} days, Rebalance: {self.rebalance_freq})')
# Plot cumulative returns
cum_strategy_plot = (cum_strategy - 1) * 100
cum_benchmark_plot = (cum_benchmark - 1) * 100
ax1.plot(data.index, cum_strategy_plot, label='Strategy', linewidth=2)
ax1.plot(data.index, cum_benchmark_plot, label=self.benchmark, linestyle=':', linewidth=2)
ax1.set_title('Cumulative Returns')
ax1.grid(True)
ax1.legend()
# Plot drawdowns
ax2.plot(data.index, drawdown_strategy, label='Strategy', linewidth=2)
ax2.plot(data.index, drawdown_benchmark, label=self.benchmark, linestyle=':', linewidth=2)
ax2.set_title('Drawdowns')
ax2.grid(True)
ax2.legend()
# Plot weights
for stock in valid_stocks:
ax3.plot(data.index, results[stock], label=stock, alpha=0.7, linewidth=1)
ax3.set_title('Portfolio Weights Evolution')
ax3.grid(True)
ax3.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()
return results
except Exception as e:
print(f"Error in portfolio analysis: {str(e)}")
return None
# Run the analysis
if __name__ == "__main__":
stocks = ["XLE", "XLU", "XLK", "XLB", "XLP",
"XLY", "XLI", "XLV", "XLF", "TLT"]
portfolio = MultiStockBPW(stocks)
results = portfolio.analyze_portfolio("2006-01-01", "2024-01-01")