Price momentum has its place in a ranking system as a way to limit downside risk for a long only strategy and can serve as a potential way to increase returns for a short system.
Industry momentum and sector momentum. As an addition to a ranking system, I have seen it improve returns time after time again.
So surely factor momentum should work too right? If momentum works for industries and individual stocks, why shouldn’t it work for factors? The logic seems so compelling—if investor herding and slow diffusion of information create trends that persist and if a factor like value, momentum, or quality has been delivering strong returns recently - there’s a reasonable case to expect that it might continue to do so in the short term. Just like it does for industries, sectors and individual stocks.
Factor momentum as an investment strategy sounds so pervasive and I really want to believe it. And I bet I'm not the only one.
So I have tried it. And I have tried so many times. But each time, my tests show that it does not work. Eventhough other investors claim its success (see for example: Factor Momentum - #2 by sthorson, Factor Momentum - #42 by yuvaltaylor and https://pracap.com/whats-driving-stocks/)
Let me show you how I think we could test it in P123.
The approach takes these steps:
-
Define factor groups
Let's take the ones from the Core Combination ranking system: Growth, Value, Quality, Low Volatility, Sentiment and Momentum and add a Size factor as well as found in this Core Combination incl. Size ranking system. -
Define a way to see whether a factor group is in momentum
2.1 One way to do it, is to create a Universe for the top quantile (top 20%) for each factor group (for example the Growth factor group). If we take the three individual factors with the highest weights in the respective node of the ranking system we can roughly measure the performance for the whole group (for example, for the factor group 'Growth' of the Core Combination ranking system, these are the factorsEPSExclXorGr%TTM,OpIncGr%PYQand%(SalesGr%PYQ, SalesGr%TTM)). For the additional Size factor, I use (66%MktCapand 34%medianvol(65)/sharescur(0))
2.2. After that, we can use that Universe to create an Aggregate series for each factor group to measure its recent performance (for example the 50 day or 200 day historical return) as well as for a benchmark. -
Define functions to calculate the (normalized) spread between the factor groups' performance vs the benchmark's performance
3.1 The functions take the form ofrespective factor's performance spread - minimum performance spread) / (maximum performance spread - minimum performance spread), where the min and max functions make sure that the spreads are normalized to positive numbers.
3.2 Here, the maximum and minimum spreads measure the maxima and minima of all the factor groups' performance spreads. -
Create a weighting function based on the normalized performance of each factor group
4.1 Calculate a sum of the normalized performance spreads.
4.2 Calculate the weighted sum for each node using the following form: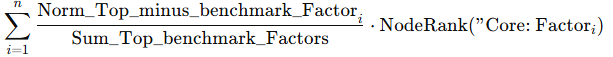 As the weights are normalised, using this formula, each weight is a decimal number between 0 and 1.
As the weights are normalised, using this formula, each weight is a decimal number between 0 and 1. -
Increase the weight of a factor group based on the weighting function
To this end, we would add the weighting function to the original ranking system to get a factor timing ranking system. We could give this node a weight of 50% such that half of the weight gets influenced by factor momentum.
Using this approach, the better a factor group performs relative to other factors groups over a 50-day period, the higher the weight that factor group will have in the ranking system for that factor group in that week. The worst factor group will not get a higher weight.
Alternatively, if we would want to allow for negative weights, we would not normalize the relative spreads and slightly adjust the weighted sum as follows:
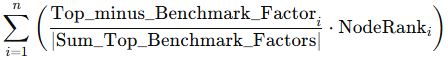 , where we sum over the non normalized spreads.
, where we sum over the non normalized spreads.
Now, the weights can be negative and float around freely. Adding this to the original ranking system, we get a factor timing ranking system that allows for negative weights.
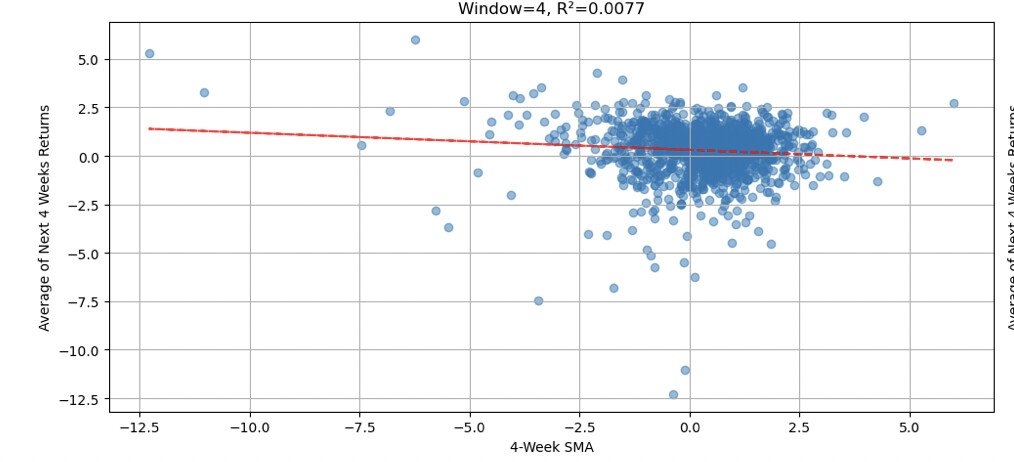
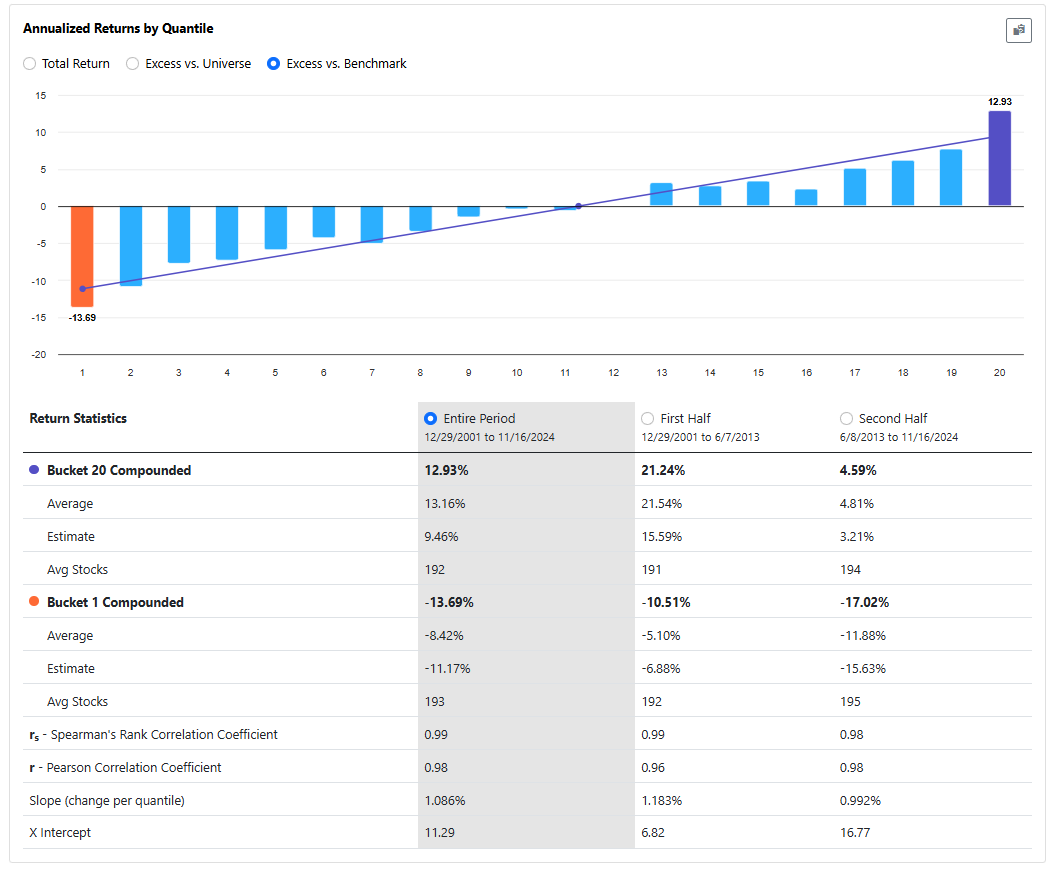
The Core Combination incl. Size ranking system on the Universe Easy to Trade US, with NA's neutral, will give these results.

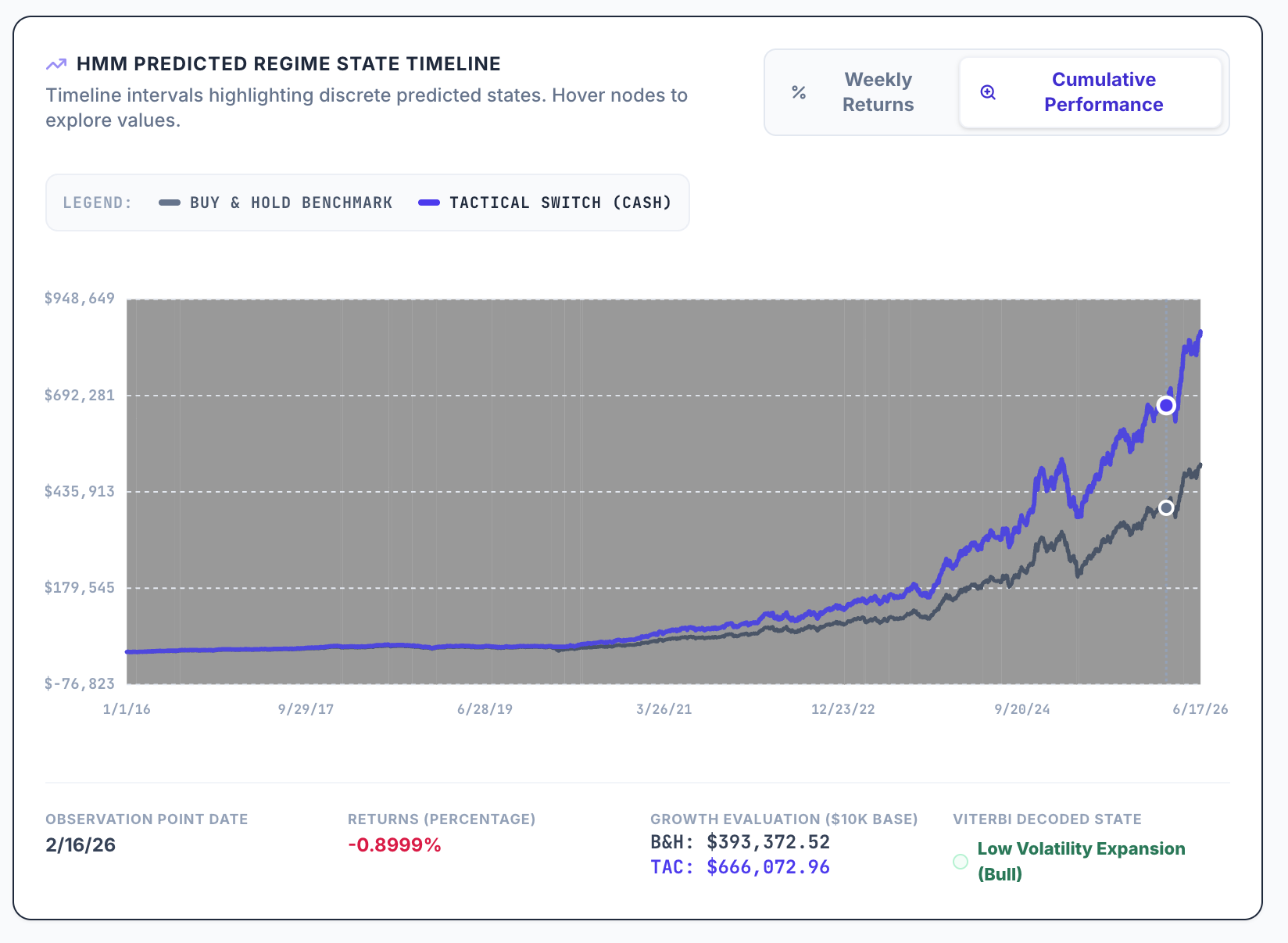
If you go through the process I described earlier and add universes, aggregate series and formulas for each factor and then run the factor timing ranking system on the Universe Easy to Trade US, with NA's neutral, you will find the following.
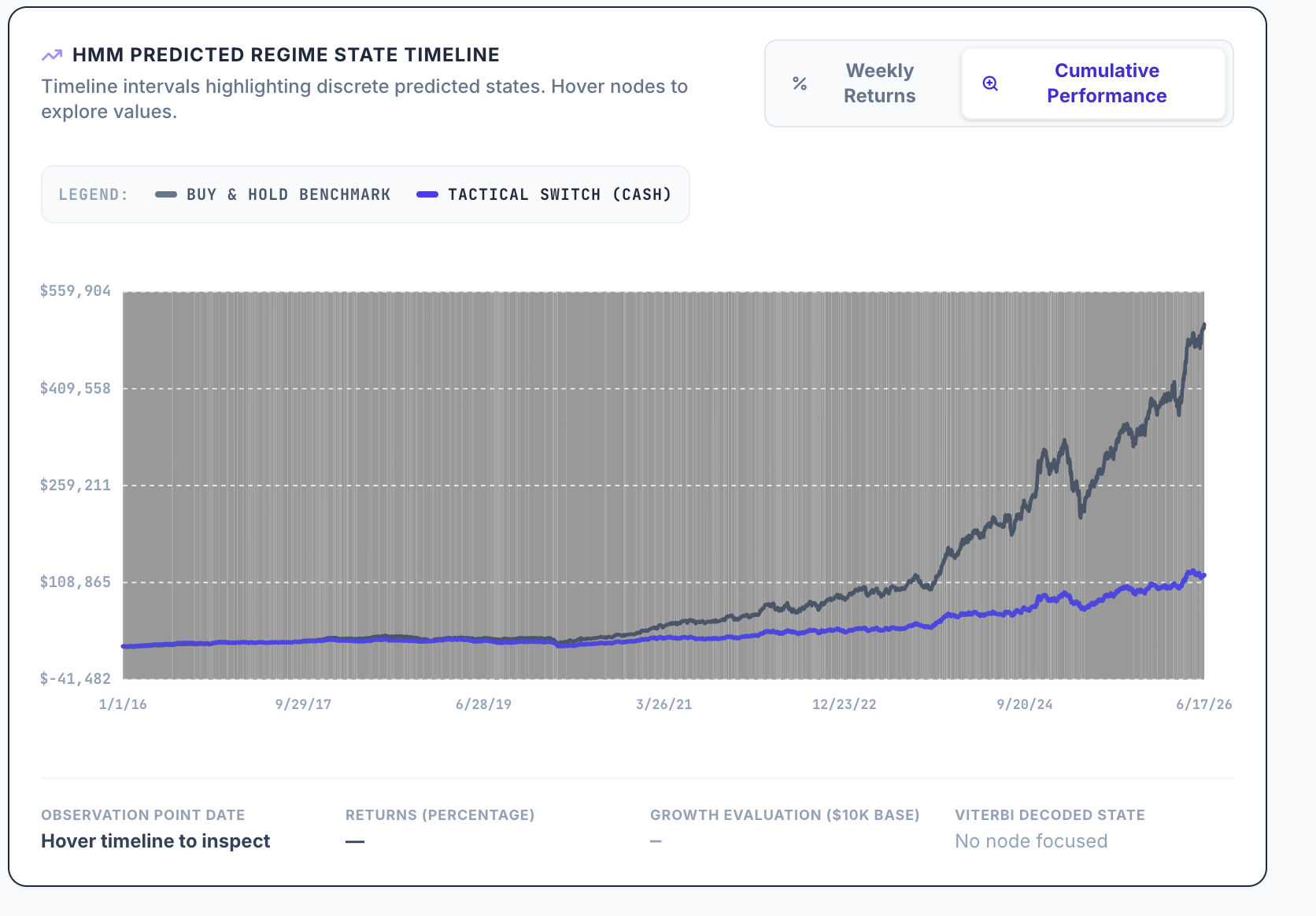
In case you run it with positive ánd negative weight adjustments with factor timing ranking system that allows for negative weights, you get:
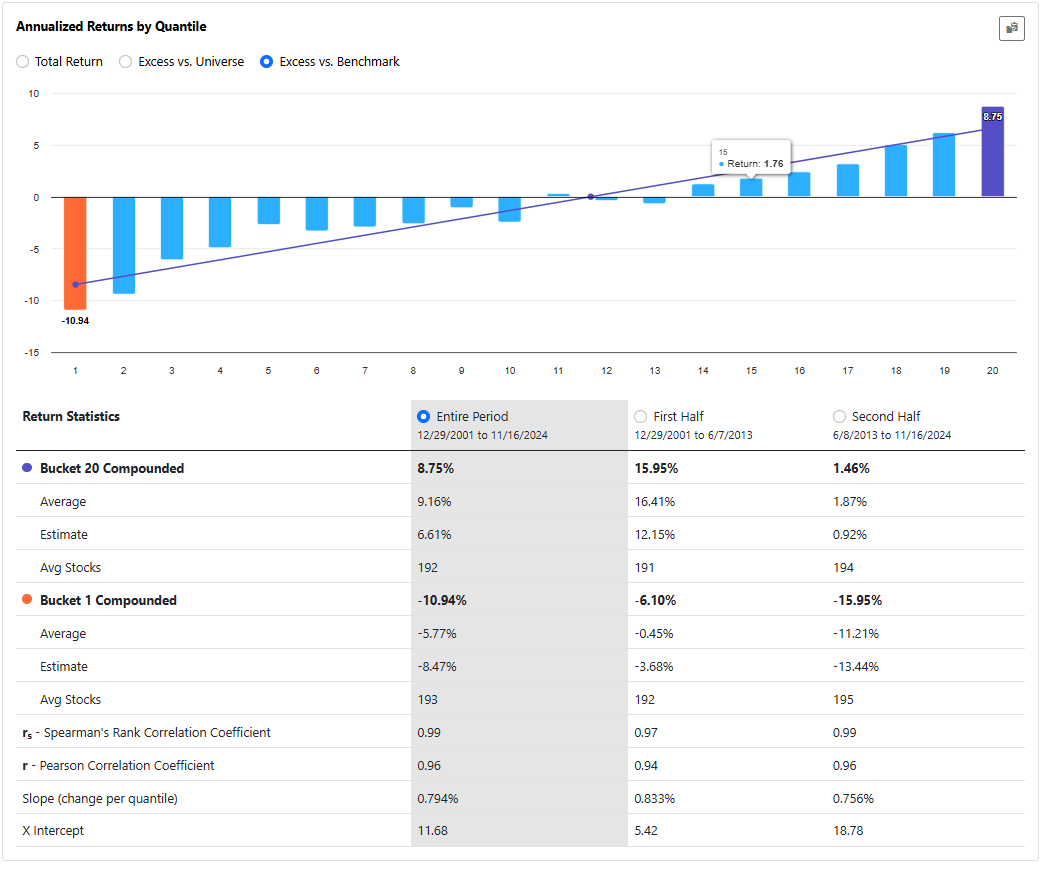
In both cases, the results are worse than the original ranking system. I get similar results when I do this for my own ranking systems.
I really wish factor momentum would work, but it seems it does not. Am I missing something fundamental? If you’ve found success with factor momentum—or if you’ve struggled with similar results—I’d love to hear your thoughts.
Best,
Victor